
Table of Contents
Fastparse is a Scala library for parsing strings and bytes into structured data. This lets you easily write a parser for any arbitrary textual data formats (e.g. program source code, JSON, ...) and have the parsers run at an acceptable speed, with great error debuggability and error reporting.
This post goes over the history and motivations of Fastparse, and what to expect with the project's recent 1.0.0 release.

About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming
The goal of Fastparse is to make it really, really easy to parsing strings into structured data. You do this by defining Parser[T] objects using the P(...) function.
import fastparse.all._
val simple = P( "hello" )
val sequenced = P( "hello" ~ " " ~ "world" )
val alternatives = P( "hello" ~ " " ~ ("world" | "World") )
val repeats = P( "hello" ~ " ".rep ~ ("world" | "World") )
Each Parser[T] object has a .parse method which lets you feed in a String and returns a Parsed.Success[T]
@ repeats.parse("hello world")
Success((), 11)
@ repeats.parse("hello World")
Success((), 14)
Or a Parsed.Failure containing diagnostic information if it failed
@ repeats.parse("hello orld")
Failure(("world" | "World"):1:10 ..."orld")
For example, the above snippet tells us that the repeats parser was expecting either world or World at line 1 column 10, but instead it saw orld and thus failed.
While the above example can easily be parsed with a regex, Fastparse makes it easy to combine parsers together (something hard to do using regexes) to parse non-trivial input formats that regexes cannot handle, such as recursive input formats. For example, here's a parser that parses-and-evaluates simple arithmetic expressions:
def eval(tree: (Int, Seq[(String, Int)])) = {
val (base, ops) = tree
ops.foldLeft(base){ case (left, (op, right)) => op match{
case "+" => left + right case "-" => left - right
case "*" => left * right case "/" => left / right
}}
}
import fastparse.all._
val number: P[Int] = P( CharIn('0' to '9').rep(1).!.map(_.toInt) )
val parens: P[Int] = P( "(" ~/ addSub ~ ")" )
val factor: P[Int] = P( number | parens )
val divMul: P[Int] = P( factor ~ (CharIn("*/").! ~/ factor).rep ).map(eval)
val addSub: P[Int] = P( divMul ~ (CharIn("+-").! ~/ divMul).rep ).map(eval)
val expr: P[Int] = P( addSub ~ End )
And here it is in use:
@ expr.parse("1+1")
Parsed.Success(2, ...)
@ expr.parse("(1+1*2)+3*4")
Parsed.Success(15, _)
@ expr.parse("((1+1*2)+(3*4*5))/3")
Parsed.Success(21, _)
@ expr.parse("1+1*")
Failure((number | parens):1:5 ..."")
What's interesting about Fastparse isn't just that it lets you parse recursive input formats that regexes cannot. What is interesting is that you can implement your parser in the same way whether you are parsing some simple query syntax, a full-fledged programming language, or some ad-hoc binary data dumps, without having to jump from tool to tool depending on the nature of the input you need to parsing.
There are example Fastparse parsers for JSON, Scala, Python, CSS. Apart from parsing Strings, Fastparse can also parse "streaming" Iterator[String]s, or binary input in the form of ByteVectors and Iterator[ByteVector] with example parsers for UDP Packets, BMP images, MIDI files, and Java Class files. Fastparse parsers run slower than hand-rolled recursive descent parsers, but with good enough performance for most purposes and great debuggability when something goes wrong.
This post will focus more on the story of why Fastparse exists, how it came to be, and where it is going. We will not go deep into how to use it: if you wish to learn more from a practical point of view, Easy Parsing with Parser Combinators provides a much more in-depth step-by-step walkthrough of the library, and the Fastparse docs are another excellent reference on what Fastparse can do and how to use it. My talk at the SF Scala meetup is also worth a watch.
The basic problem Fastparse is trying to solve is that there is a gap in the tools you can use to parse things:
For really simple formats, you can use String.split to break it into constituent parts for you to use: e.g. splitting a file based on lines, then splitting each line based on tabs.
For less simple formats, you can use a regex: hello *(world|World) can parse the hello-world example above, and you can use capturing groups to grab the parts of the input you want.
For complex formats, where you need the utmost in performance and customizability, you can use hand-rolled recursive descent parsers, or a parser generator like Bison or ANTLR
In between "regex" and "recursive-descent/parser-generator", there is a gap: what about the cases where you don't need utmost performance, but your data format is too complex to use a regex? Hand-rolled recursive descent parsers are straightforward but tedious to write, while parser generators are finnicky to set up and often require custom build steps and code-generation.
Why can't there be a way of writing parsers as simple as a regex, but as flexible as hand-rolled recursive-descent parsers or parser generators? It turns out there are such things: they're called Parser Combinators, and Fastparse is one such library in that category.
Fastparse is not the first Parser Combinator library. Other parser combinator libraries include:
Parsec, Attoparser, Megaparsec in Haskell
FParsec in F#
Pyparsing in Python
Boost.Spirit in C++
Nom in Rust
Parsimmon in Javascript
The different libraries in different languages are different in many ways: different execution model, different performance characteristics and error reporting, etc.. However, they all share the same few properties that make them "parser combinator" libraries:
Parsers are just normal objects/functions you define anywhere in your code, not something special you have to code-generate like in Bison or ANTLR
They provide basic parsers (e.g. parsing literal strings) and a way to combine those into more complex parsers (e.g. repeating a parser, running parsers one-after-another in sequence, running one parser but trying another if the first one fails) often referred to as "combinators"
They are able to parse input formats more complex than what a regex can handle, often just as complex as what input formats parser-generators or hand-rolled recursive-descent can handle
Performance that lags behind what a parser-generators or hand-rolled recursive-descent parser would provide, but is "good enough" for many/most use cases
Fastparse is also not the first parser combinator library I've used. In fact, it isn't the first parser combinator library I've written! Nevertheless, it is one in a long lineage of related libraries, one that happens to occupy a sweet spot in terms of performance, flexibility and ease-of-use that it's gotten reasonably popular within the Scala community.
In software engineering, parsing input into structured data is one of the perennial tasks you have to do: whether you reach for a standard parser for a standard format such as for JSON, or you're writing your own parser for some log-files you need to process, or you're taking user-input in some configuration language. Whether doing game-dev, web-dev, writing operating systems or distributed networks, you are going to bump into things you need to parse.
One thing I've long wondered was the prevalence of parser-generators and similar tools: why do parsing libraries use code-generation? After all, in most other tasks, you simply have a library whose functions you call: rarely do you find yourself generating code programmatically. In writing parsers for parsing user query strings, document markup or HTML templates, I've always felt there had to be a better way.
It was in the writing of an experimental markup language XMLite that I discovered parser-combinators as an alternative to regexes/hand-rolled-recursive-descent/parser-generators, in the form of the Scala Parser Combinators library.
def root = jsonObj | jsonArray
def jsonObj = "{" ~> repsep(objEntry, ",") <~ "}" ^^ { case vals : List[_] => JSONObject(Map(vals : _*)) }
def jsonArray = "[" ~> repsep(value, ",") <~ "]" ^^ { case vals : List[_] => JSONArray(vals) }
def objEntry = stringVal ~ (":" ~> value) ^^ { case x ~ y => (x, y) }
def stringVal = accept("string", { case lexical.StringLit(n) => n} )
def number = accept("number", { case lexical.NumericLit(n) => numberParser.get.apply(n)} )
def value: Parser[Any] = (jsonObj | jsonArray | number | "true" ^^^ true | "false" ^^^ false | "null" ^^^ null | stringVal)
Scala Parser Combinators demonstrated to me the promise of parser combinators: the ability to write your parser in "normal code", without needing special code-generation steps or loads of recursive-descent boilerplate. Many aspects of Scala Parser Combinators, such as the "cut" ~! (used to reduce backtracking and improve error reporting) or log (used in debugging to figure out what's going on) operations were great ideas and would eventually find their way into Fastparse.
This particular library has many shortcomings: performance was poor, error reporting wasn't great, and it used far more cryptic operators (~>, <~, ^^, ^^^, ...) than was really necessary, it's .log debugger wasn't as useful as it could have been. Although I was certainly not uses the library optimally, my parsers built using this library were slow enough that even my relatively small test suite with a few thousand lines of input was taking multiple seconds to parse. That definitely wouldn't work for many non-toy use cases!
The XMLite project hasn't gone anywhere (yet) but that was my first experience with the concept of "Parser Combinators", and I thought they were really cool.
Inspired by Scala Parser Combinators, I ended up writing a mostly-identical parser-combinator library called MacroPEG, as a demosntration of using the MacroPy Python extension library. Even though I had zero background in formal language theory or programming language theory, it turns out that implementating of a parser combinator library isn't hard: MacroPEG is only ~450 lines of code, but can implement the same arithmetic parser we saw above, and a JSON parser similar to the one in the Fastparse example parser collection.
def reduce_chain(chain):
chain = list(reversed(chain))
o_dict = { "+": f[_+_], "-": f[_-_], "*": f[_*_], "/": f[_/_] }
while len(chain) > 1:
a, [o, b] = chain.pop(), chain.pop()
chain.append(o_dict[o](a, b))
return chain[0]
# MacroPEG parser
with peg:
op = '+' | '-' | '*' | '/'
value = '[0-9]+'.r // int | ('(', expr, ')') // f[_[1]]
expr = (value, (op, value).rep is rest) >> reduce_chain([value] + rest)
# Usage
expr.parse("123") == 123
expr.parse("((123))") == 123
expr.parse("(123+456+789)") == 1368
expr.parse("(6/2)") == 3
expr.parse("(1+2+3)+2") == 8
expr.parse("(((((((11)))))+22+33)*(4+5+((6))))/12*(17+5)") == 1804
Like XMLite, MacroPEG and MacroPy, no matter how cool I thought they were, have not taken off. Nevertheless, MacroPEG demonstrated to me how easy it was to write a parser combinator library. If a total newbie with no real background can write a working/easy-to-use library in 450 lines of code, how hard can it be, eh?
Scalaparse, a Scala parser implemented in Fastparse and used in my Scalatex doc-site generator, actually pre-dates Fastparse: it was originally written using Mathias Doenitz's Parboiled2 library. I needed a mostly-correct Scala parser (this was a doc markup syntax after all, not "full" Scala), and the Scala compiler's parser was too tangled with the rest of the compiler to be extracted and used.
Parboiled2 is a performance-focused parser combinator library in Scala: syntactically it looks similar to Scala Parser Combinators, but under the hood it uses macros and all sorts of tricks to make things run faster. The result is that Parboiled2 is almost 100 times faster than Scala Parser Combinators, and within a factor of 2-4 of the fastest, hand-optimized recursive descent parsers (see benchmarks). Unlike Scala Parser Combinators, Parboiled2 is fast enough for real-world usage, and is used in many production libraries and deployments.
The problem with Parboiled2 was in the usability of the library. While its performance was far better than Scala Parser Combinators when you got things working, trying to get things working in the first place was an exercise in frustration. Complicated usage instructions, un-specified behavior in case of errors, lack of debugging tools, use cases that don't work for mysterious reasons, and terrifying compile errors:
[error] /Users/haoyi/Dropbox (Personal)/Workspace/scala-js-book/scalatexApi/src/main/scala/scalatex/stages/Parser.scala:16: type mismatch;
[error] found : shapeless.::[Int,shapeless.::[scalatex.stages.Ast.Block,shapeless.HNil]]
[error] required: scalatex.stages.Ast.Block
[error] new Parser(input, offset).Body.run().get
[error] ^
[error] /Users/haoyi/Dropbox (Personal)/Workspace/scala-js-book/scalatexApi/src/main/scala/scalatex/stages/Parser.scala:60: overloaded method value apply with alternatives:
[error] [I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[I,shapeless.::[J,shapeless.::[K,shapeless.::[L,shapeless.::[M,shapeless.::[N,shapeless.::[O,shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[J,shapeless.::[K,shapeless.::[L,shapeless.::[M,shapeless.::[N,shapeless.::[O,shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[K,shapeless.::[L,shapeless.::[M,shapeless.::[N,shapeless.::[O,shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[L,shapeless.::[M,shapeless.::[N,shapeless.::[O,shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[M,shapeless.::[N,shapeless.::[O,shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [N, O, P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[N,shapeless.::[O,shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(N, O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [O, P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[O,shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(O, P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [P, Q, R, S, T, U, V, W, X, Y, Z, RR](f: (P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[P,shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(P, Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [Q, R, S, T, U, V, W, X, Y, Z, RR](f: (Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[Q,shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(Q, R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [R, S, T, U, V, W, X, Y, Z, RR](f: (R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[R,shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(R, S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [S, T, U, V, W, X, Y, Z, RR](f: (S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[S,shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(S, T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [T, U, V, W, X, Y, Z, RR](f: (T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[T,shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(T, U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [U, V, W, X, Y, Z, RR](f: (U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[U,shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(U, V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [V, W, X, Y, Z, RR](f: (V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[V,shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(V, W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [W, X, Y, Z, RR](f: (W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[W,shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(W, X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [X, Y, Z, RR](f: (X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[X,shapeless.::[Y,shapeless.::[Z,shapeless.HNil]]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(X, Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [Y, Z, RR](f: (Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[Y,shapeless.::[Z,shapeless.HNil]],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(Y, Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [Z, RR](f: (Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.::[Z,shapeless.HNil],shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(Z, scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [RR](f: (scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.HNil,shapeless.HNil,RR], implicit c: org.parboiled2.support.FCapture[(scalatex.stages.Ast.Block.Text, scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [RR](f: (scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.HNil,shapeless.::[scalatex.stages.Ast.Block.Text,shapeless.HNil],RR], implicit c: org.parboiled2.support.FCapture[(scalatex.stages.Ast.Chain, Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [RR](f: (Int, scalatex.stages.Ast.Block) => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.HNil,shapeless.::[scalatex.stages.Ast.Block.Text,shapeless.::[scalatex.stages.Ast.Chain,shapeless.HNil]],RR], implicit c: org.parboiled2.support.FCapture[(Int, scalatex.stages.Ast.Block) => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [RR](f: scalatex.stages.Ast.Block => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.HNil,shapeless.::[scalatex.stages.Ast.Block.Text,shapeless.::[scalatex.stages.Ast.Chain,shapeless.::[Int,shapeless.HNil]]],RR], implicit c: org.parboiled2.support.FCapture[scalatex.stages.Ast.Block => RR])org.parboiled2.Rule[j.In,j.Out] <and>
[error] [RR](f: () => RR)(implicit j: org.parboiled2.support.ActionOps.SJoin[shapeless.HNil,shapeless.::[scalatex.stages.Ast.Block.Text,shapeless.::[scalatex.stages.Ast.Chain,shapeless.::[Int,shapeless.::[scalatex.stages.Ast.Block,shapeless.HNil]]]],RR], implicit c: org.parboiled2.support.FCapture[() => RR])org.parboiled2.Rule[j.In,j.Out]
[error] cannot be applied to ((scalatex.stages.Ast.Chain, scalatex.stages.Ast.Block) => scalatex.stages.Ast.Chain)
[error] IndentBlock ~> {
[error] ^
[error] /Users/haoyi/Dropbox (Personal)/Workspace/scala-js-book/scalatexApi/src/main/scala/scalatex/stages/Parser.scala:71: The `optional`, `zeroOrMore`, `oneOrMore` and `times` modifiers can only be used on rules of type `Rule0`, `Rule1[T]` and `Rule[I, O <: I]`!
[error] push(offsetCursor) ~ IfHead ~ BraceBlock ~ optional("else" ~ (BraceBlock | IndentBlock))
[error] ^
[error] /Users/haoyi/Dropbox (Personal)/Workspace/scala-js-book/scalatexApi/src/main/scala/scalatex/stages/Parser.scala:74: The `optional`, `zeroOrMore`, `oneOrMore` and `times` modifiers can only be used on rules of type `Rule0`, `Rule1[T]` and `Rule[I, O <: I]`!
[error] Indent ~ push(offsetCursor) ~ IfHead ~ IndentBlock ~ optional(Indent ~ "@else" ~ (BraceBlock | IndentBlock))
[error] ^
[error] /Users/haoyi/Dropbox (Personal)/Workspace/scala-js-book/scalatexApi/src/main/scala/scalatex/stages/Parser.scala:91: type mismatch;
[error] found : Int
[error] required: String
[error] ((a, b, c) => Ast.Block.For(b, c, a))
[error] ^
[error] /Users/haoyi/Dropbox (Personal)/Workspace/scala-js-book/scalatexApi/src/main/scala/scalatex/stages/Parser.scala:112: type mismatch;
[error] found : org.parboiled2.Rule[shapeless.HNil,shapeless.::[Int,shapeless.::[scalatex.stages.Ast.Block,shapeless.HNil]]]
[error] required: org.parboiled2.Rule[shapeless.HNil,shapeless.::[scalatex.stages.Ast.Block,shapeless.HNil]]
[error] def BraceBlock: Rule1[Ast.Block] = rule{ '{' ~ BodyNoBrace ~ '}' }
[error] ^
[error] 6 errors found
[error] (scalatexApi/compile:compile) Compilation failed
[error] Total time: 9 s, completed Nov 10, 2014 7:57:23 AM
The Parboiled2 version of Scalaparse was completed, worked, and completed its tour of duty supporting Scalatex. The experience of working with Parboiled2 was frustrating, but it did demonstrate one thing: parser combinators didn't need to be slow, as Scala Parser Combinators was. Parsers written using Parboiled2, despite their problems, were blazing fast.
At this point, I was wondering: if parser combinators can be easy-to-use, and parser combinators can be fast, why can't parser combinators be easy-to-use and fast? Given that MacroPEG had shown me that parser combinator libraries were also easy to implement, it seemed reasonable I could take a crack at implementing a parser combinator library that would give me the best of both worlds.
Fastparse started as a drop-in replacement for Parboiled2, to support the already-written Scalaparse library. Scalaparse was already written and working, but it was still undergoing improvements, and it was exceedingly difficult diagnose/debug/fix Scalaparse issues due to Parboiled2's usability issues. Re-writing Scalaparse to us Scala Parser Combinators was considered, but I judged them to be too slow for this: if they could take noticable time parsing my simple XMLite markup language, they would take forever parsing the complex Scala syntax! Hence Fastparse was meant to fix that.
The original Fastparse code looked about the same as the MacroPEG code I had written earlier, except translated from Python into Scala.
From the git log, I started work on Fastparse at 9am on a Sunday:
commit e642e103e2daa3dbb3df7e3ad20076708759759c
Author: Li Haoyi <haoyi@dropbox.com>
Date: Sun Apr 26 09:48:58 2015 -0700
.
By 5pm, it was "complete" enough to successfully compile Scalaparse but not to run it:
commit c5d897ce2b8115317da2a12a2cc34b5630016906
Author: Li Haoyi <haoyi@dropbox.com>
Date: Sun Apr 26 17:14:32 2015 -0700
`scalaParser` compiles using `parsing.Parsing`, nothing works yet
And by 9pm that day, it was complete enough to run Scalaparse and successfully parse it's first non-trivial (~4000 line) Scala file:
commit 92ede77d028dcd2f40e20cba81d0278e44d775fe
Author: Li Haoyi <haoyi@dropbox.com>
Date: Sun Apr 26 21:28:18 2015 -0700
Parsing `GenJSCode` now works
So it took only 12 hours to write a parser combinator library complete enough to satisfy my use case in Scalaparse, and cut over to using the new library. Turns out that my feeling that "parser combinators are easy to implement" was right! And that's where Fastparse came from.
While a lot more work went into Fastparse in the days after it was initially written. The git log around that time documents the changes, although you may have to look at the code because my commit message hygiene wasn't great...
commit 8e46760c01f0a04668c1239d425bef40c361f398
Author: Li Haoyi <haoyi@dropbox.com>
Date: Sun May 3 18:36:00 2015 -0700
Cneaup
Major efforts around that time were:
Fixing all the bugs that were causing Scalaparse to behave incorrectly, compared to how it behaved under Parboiled2
Fixing bugs in Scalaparse that were discovered by feeding it more Scala source code from open-source codebases
Implement and make use of "cuts", which are present in Scala Parser Combinators and MacroPEG but not in Parboiled2. These greatly improve the error messages a parse fails
Measuring and trying to optimize performance of the library
After the initial activity trying to get Fastparse to be feature-complete enough to support Scalaparse (and replace Parboiled2), there were two main pushes:
Fastparse is implemented following the classic Interpreter Pattern. Every Parser[T] is an object with a .parse method, which either returns a Success[T] (which contains a result value T) or a Failure containing diagnostic information. .parse is opaque, and what that method does is entirely up to the parser: anyone can implement their own Parser[T] by defining a .parse method! While parser combinators are often thought of as a "functional programming" thing you see in languages like Haskell of F#, the design of Fastparse is about as classic OO-style design-patterns as you can get.
Fastparse is fundamentally an interpreter: combining parsers is like combining AST nodes, while .parse recurses over the parsers like how an interpreter recurses over an AST. That means that it suffers from "interpreter overhead": some CPU time is always spent walking the AST and deciding what to do, which means it will always be less efficient at doing the "real work" of parsing. This is in contract to a hand-rolled recursive descent parser or a macro-based "direct" style parser combinator library like Parboiled2, where 100% of the time is spent parsing.
However, while theoretically a Fastparse parser will always be slower than a hand-optimized parser, it's an empirical question exactly how much slower it needs to be.
Fastparse turns out to be about 4x slower than the fastest hand-written JSON parser on the JVM, and about 10-15x slower than the hand-written Scala compiler parser. This is slower than Parboiled2, which is 4x and 4x slower respectively, but much faster than Scala Parser Combinators, which is 300x slower (!) than hand-written parsers.
A lot of work went into optimizing the Fastparse internals to make the fast. Key techniques include:
Scala Parser Combinators, and many other similar libraries, rely heavily on the Parser[T]#flatMap(f: T => Parser[V]) method, even when not strictly necessary. For example, consider the way the sequence-with-cut operator is implemented in Scala Parser Combinators:
def ~ = OnceParser{
(
for(a <- this; b <- commit(p))
yield new ~(a, b)
).named("~!")
}
In Scala, for loops are equivalent to map and flatMap calls, so the above becomes:
def ~ = OnceParser{
this.flatMap{a =>
commit(p).map{b =>
new ~(a, b)
}
}.named("~!")
}
Here, you can see that in a simple combination parser this ~ p, which needs to run this and p in sequence, we end up creating a bunch of anonymous functions and passing them into a bunch of flatMap and map calls every single time. This generates a lot of garbage (all those anonymous functions need to get garbage-collected later!), and runs a lot more code than you really need to run just to parse two things one-after-the-other.
Fastparse avoids this: while it also supports .flatMap, which necessarily does a bunch of allocations, the this ~ p parser is special-cased to use a different code-path than what flatMap uses. This lets this ~ p, which is the overwhelmingly common case, be much faster than if we relied on using .flatMap all the time. When you do call .flatMap, it will naturally be a bit slower, but actually needing to call .flatMap is rare enough (e.g. Scala parser uses it 0 times, Python parses uses it 1 time, ...) that this isn't a problem in general.
Another thing that's common in parser combinator libraries is that each call to .parse will return a new result containing what that parser parsed: maybe it parsed nothing (Unit), maybe a String, maybe a Seq[Int]. Every time a parser returns something, it allocates a new Result object to put that Unit, String, or Seq[Int] into so that it has something to return.
This makes a lot of sense from a logical perspective: every parser returns a result, and the results are independent. However, it is somewhat wasteful from an implementation perspective: you're constantly creating and discarding Result objects, whereas you really only need a single Result object at any one point in time.
Fastparse thus uses mutable Mutable.Success and Mutable.Failure objects internally when interpreting a parser, only converting it to an immutable Parsed.Success or Parsed.Failure when Fastparse is ready to hand control back to the user. e.g. here is the implementation of the FlatMapped parser, returned by the .flatMap operation:
case class FlatMapped[T, V, Elem, Repr](p1: Parser[T, Elem, Repr], func: T => Parser[V, Elem, Repr])
(implicit repr: ReprOps[Elem, Repr])
extends Parser[V, Elem, Repr] {
def parseRec(cfg: ParseCtx[Elem, Repr], index: Int) = {
p1.parseRec(cfg, index) match{
case f: Mutable.Failure[Elem, Repr] => failMore(f, index, cfg.logDepth, cut = false)
case s: Mutable.Success[T, Elem, Repr] =>
val sCut = s.cut
val res = func(s.value).parseRec(cfg, s.index)
res.cut = sCut
res
}
}
override def toString = p1.toString
}
See how while the "public" interface of the parser is .parse, internally the parser is implemented using the .parseRec method. .parseRec deals with Mutable.Success and Mutable.Failure objects, which are re-used throughout a single parse run. Furthermore, since they're mutable, we need to be really careful to save e.g. the attribute s.cut into a local variable sCut, if we want to access it later, since s.cut will get stomped over by some other value when we call func(s.value).parseRec(...).
Throughout Fastparse's internals, we have to be extra-careful in handling the mutable result objects. However, it makes the parser run a lot faster, and the user of Fastparse still gets a nice, immutable result back, and can simply enjoy the speedup of their parser running significantly faster.
Many parser combinator libraries return a tuple/sequence every time you run parsers in sequence. For example, in Scala Parser Combinators, the parser
val parser = "hello" ~ " " ~ ("world" | "World")
When called via
parse(parser, "hello world")
Will return the object
~(~("hello", " "), "world")
After that, it's up to the user to pattern match on that result, and discard the bits they don't want. For example, in this case the only thing that can change is "world" | "World", so that's all we care about:
val parser = ("hello" ~ " " ~ ("world" | "World")).map{
case ~(~(helloStr, spaceStr), worldStr) => worldStr
// Different syntax for the same thing:
case helloStr ~ spaceStr ~ worldStr => worldStr
}
parse(parser, "hello world") // "world"
This works, but is wasteful: you end up creating a bunch of tuples (or ~(a, b) tuple-like objects) just to discard them later. Typically, in most parsers, you do not care about "most" things the parser sees: if you're parsing JSON for example, you don't care about whitespace, {} curlies, [] brackets, or , commas: these all do not make their way into the final parsed data structure. Allocating tuples for all of them, just to discard them later, is wasteful.
Fastparse does the opposite: nothing allocates a result, unless you explicitly ask for it. Thus the above Fastparse parser would be written like:
val parser = P( "hello" ~ " " ~ ("world" | "World").! )
Where the .! tells Fastparse you want to capture the string:
parser.parse("hello world") // "world"
If you capture multiple things, they still get added into a tuple:
val parser = P( ("hello" | "Hello").! ~ " " ~ ("world" | "World").! )
parser.parse("hello world") // ("hello", "world")
But what's important is that we never allocate tuples for the things you don't want to capture. In many cases, the things you don't want to capture vastly outnumber the things you do want to capture, and Fastparse saves on allocating-and-discarding all those tuples containing unwanted results.
The last major thing that Fastparse does is provide fast building blocks that perform common operations. Things like the CharsWhile parser:
val cw = P( CharsWhile(_ != ' ').! )
val Parsed.Success("12345", _) = cw.parse("12345")
val Parsed.Success("123", _) = cw.parse("123 45")
CharsWhile does something every parser-writer wants to do at some point: consume a whole bunch of characters while some predicate holds. While you could implement this using repeat (.rep) and other operators:
val cw = P( (!" " ~ AnyChar).rep(1).! )
val Parsed.Success("12345", _) = cw.parse("12345")
val Parsed.Success("123", _) = cw.parse("123 45")
CharsWhile runs much faster than the pieced-together equivalent: it's literally a while-loop incrementing a counter, it doesn't get much faster than that!
These fast intrinsics are key to making Fastparse parsers fast. Using them means that while parsing the non-trivial parts of an input may be slower than a hand-optimized parser, parsing the trivial parts (e.g. large blocks of white-space, the contents of string literals, end-of-line comments, ...) is just as fast. This is part of the reason why the Fastparse JSON parser, whose input is mostly string-literals and whitespace, performs closer to hand-written performance compared to the Fastparse Scala parser.
This was a project done over Google Summer of Code by Vladimir Polushin. The motivation is that nothing in Fastparse is really specific to parsing a single String input: we should be able to parse streaming input, and we should be able to parse binary input, using exactly the same logic.
The basic issue with streaming input is that it prevents backtracking: you can't backtrack to an earlier point in the stream if you've already consumed those characters and discarded them! However, FastParse does have a mechanism for which you can control backtracking: Cuts!
Without cuts, any parser could fail and backtrack all the way to the start of the input. Consider the following case
import fastparse.all._
val parser = P( "hello" ~ " " ~ "world" | "world" ~ " " ~ "foo" ~ " " ~ "bar" )
parser.parse("hello foo bar")
parser would first attempt the left-hand-side of the alternative |, and parse "hello" and " " successfully. However, after that it would find the next characters are "foo" while it expects a "world": it would thus thus backtrack to where it was before attempting the left-hand-side, in this case to the start of the input, and then attempt the right-hand-side of the |. The right-hand-side parse would then succeed.
However, in the following case:
import fastparse.all._
val parser = P( "hello" ~ " " ~ "world" | "foo" ~ " " ~ "bar" ~ " " ~ "baz" )
parser.parse("hello foo bar")
parser would make similarly attempt-and-fail-to-parse the left-hand-side. However, parser isn't smart enough to know that having seen "hello" means the right-hand-side could never pass without trying it, so it will still need to backtrack all the way to the start of the input in order to give it a shot, see it fail, and report a failure:
expected "hello" ~ " " ~ "world" | "foo" ~ " " ~ "bar" ~ " " ~ "baz", received
"foo" at index 0
Because it doesn't know which side of the alternative | was "meant" to have passed, all it can do is tell you both sides failed.
To support this backtracking, we would need to buffer the entire streaming input in memory so the parser could backtrack and look at it. This would defeat the purpose of streaming input.
With cuts, things are better: we only need to backtrack as far as the latest cut happened. e.g. in the following case:
import fastparse.all._
val parser = P( "hello" ~/ " " ~ "world" | "foo" ~/ " " ~ "bar" ~ " " ~ "baz" )
parser.parse("hello foo bar")
We use "cuts" (~/ operator) to tell FastParse "if you reach this point in the branch of the alternative, do not backtrack because it means the other branches cannot possibly succeed". This has two results:
We get a more precise error message expected "world", received "foo" at index
5, since it knows not to bother backtracking and trying the right-hand-side branch
As the parser reaches these cuts, we can safely discard earlier parts of the input buffer, since we can no longer backtrack past them!
The second point is important when taking streaming input: it helps us keep the size of the buffer bounded. And placing cuts in your parser is something you should be doing anyway, in order to improve error messages when a parse fails.
The documentation for streaming inputs demonstrates this phenomena for real-world parsers on real-world inputs:
| Parser | Max buffer for 1-sized chunk | Max buffer for 1024-sized chunk | Input Size | Used memory |
|---|---|---|---|---|
| ScalaParse | 1555 | 2523 | 147894 | 1.4% |
| PythonParse | 2006 | 2867 | 68558 | 3.6% |
| BmpParse | 36 | 1026 | 786486 | 0.01% |
| ClassParse | 476 | 1371 | 332142 | 0.3% |
Parsing 148kb of Scala code, Scalaparse only needs a buffer of 1500-2500 characters (depending on how big the streaming chunks are) in order to support backtracking. The Python, BMP image, and Java Classfile parsers show similar numbers.
It turns out that for real-world parsers of real-world data formats, it is perfectly possible to do streaming parsing even in the presence of backtracking, with only a small amount of buffering.
The core of Fastparse - parsing A then B, or parsing A multiple times, or trying to parse A then trying B if A fails - is not unique to parsing strings. Over the course of GSOC, Vladimir managed to make the entire library generic in what type is being parsed, while maintaining source-compatibility for the public interface of the library! Now, instead of Parser[T] meaning something that parses a String into a T, Parser[T] is just an alias for some kind of generic.Parser[String, Char, T], and you could easily have a generic.Parser[ByteVector, Byte, T] that would parse a binary input. a ~ b, a | b, a.rep, etc. all apply the same way to binary input as they do to strings.
While we'd need to handle some things differently between Strings and ByteVector inputs, the vast majority of the code should be able to be shared. And in Pull Request #93, it became the case.
Here's a UDP-packet parser which demonstrates the usage:
import fastparse.byte.all._
case class UdpPacket(sourcePort: Int,
destPort: Int,
checkSum: Int,
data: Bytes)
// BE.UInt16 stands for big-endian unsigned-16-bit-integer parsers
val udpHeader = P( BE.UInt16 ~ BE.UInt16 ~ BE.UInt16 ~ BE.UInt16 )
val udpParser = P(
for{
(sourcePort, destPort, length, checkSum) <- udpHeader
data <- AnyBytes(length - 8).!
} yield UdpPacket(sourcePort, destPort, checkSum, data)
)
And here's the usage of it:
val bytes = hex"""
04 89 00 35 00 2C AB B4 00 01 01 00 00 01 00 00
00 00 00 00 04 70 6F 70 64 02 69 78 06 6E 65 74
63 6F 6D 03 63 6F 6D 00 00 01 00 01
"""
val Parsed.Success(packet, _) = udpParser.parse(bytes)
assert(
packet.sourcePort == 1161,
packet.destPort == 53,
packet.checkSum == 43956,
packet.data.length == 36,
packet.data == hex"""
00 01 01 00 00 01 00 00 00 00 00 00 04 70 6F 70
64 02 69 78 06 6E 65 74 63 6F 6D 03 63 6F 6D 00
00 01 00 01
"""
)
As you can see, we're using primitives like BE.UInt16 (BE stands for big endian) instead of strings like "hello", and we're using .flatMap ia the for-comprehension (which we don't use much when parsing strings) but otherwise the parse is structured more-or-less identically to any of the String parsers we saw above. We basically got an entire binary parsing library, in addition to our existing string parsing library, for the cost of only a small set of changes to Fastparse to support it.
Version 1.0.0 is 100% identical to version 0.4.4, which itself was 100% identical to version 0.4.3. The only things that "happened" were that Scala-Native started stabilizing, and we published artifacts to support anyone who wants to use Fastparse (both the string and binary parsing APIs) on Scala-Native. This is in addition to support for Scala.js, which Fastparse has had since forever.
Rather than a chance to break backwards compatibility and make sweeping changes, 1.0.0 is simply a marker of stability. Apart from a few bug fixes in the example parsers, and publishing for new versions of Scala, FastParse has barely changed at all in the last 12 months since binary/streaming parsing was released in September 2016. All this while, usage of Fastparse has been growing, with tens of thousands of monthly downloads at a rate increasing steadily month after month:
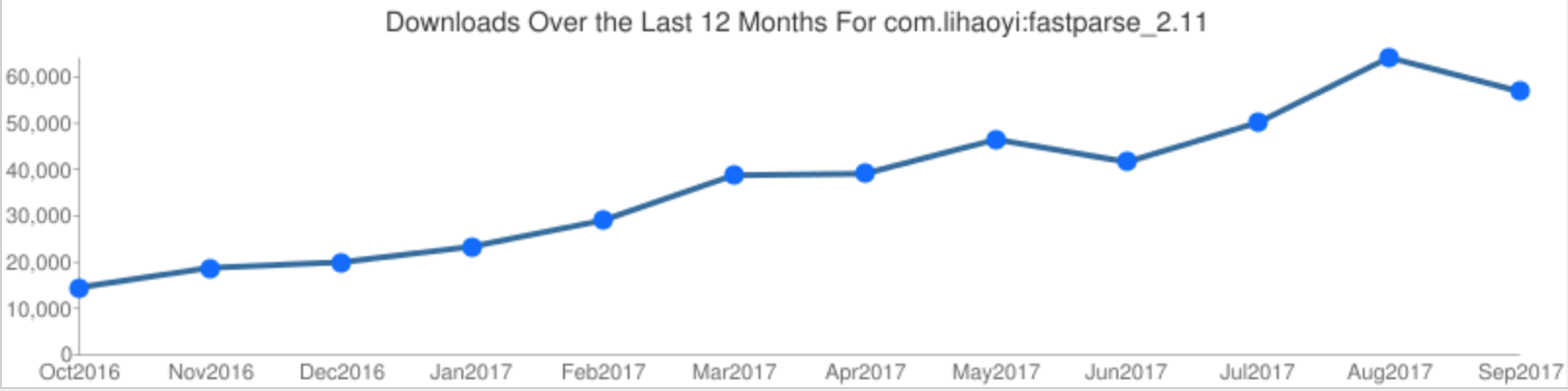
There are few open issues. A few inconsistent APIs like #164, some edge-cases like #169 or #88 where there's no "obvious" correct behavior. Only one un-investigated open bug in #135. Fastparse is clearly being used for a lot of people, and they don't seem to have much to say about it. Like we used to say at Dropbox, it just works.
From an implementation point of view, Fastparse has stabilized. In its current design, as a fast immutable interpreter, I don't expect to see any major adjustments or changes in the future. Some features like parser traversal #158 may be nice to have, but aren't really critical, and furthermore can probably be implemented without breaking backwards compatibility.
There are always more radical ideas of how things could change: perhaps we could write a two-way parsing/serialization library like Scodec, or adding macro-powered compile-time optimizations like in Parboiled2, or making Fastparse build "direct-style" non-interpreter parsers as I've prototyped in FasterParser. While those directions all seem plausible, none are obvious improvements, and all seem antithetical to what Fastparse is: at some point it's easier just to create a whole new parsing library called something else. Fastparse already does all it was meant to do, and it does it well and seemingly without issue.
Fastparse will continue to be maintained. As further versions of Scala, Scala.js or Scala-Native come out, it's easy to publish artifacts to support them. If someone reports new bugs, I'll take a look, but given how few bugs turned up over the last year I don't expect much to come in. If someone proposes backwards-compatible performance improvements, I'll happily merge them.
So that's what Version 1.0.0 is all about: Fastparse is now stable, and this was the journey to get here.
About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming