
Table of Contents
JSON HTTP APIs have become the standard for any organization exposing parts of their system publicly for external developers to work with. This tutorial will walk you through how to access JSON HTTP APIs in Scala, building up to a simple use case: migrating Github issues from one repository to another using Github's public API.

About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming
The easiest way to work with JSON HTTP APIs is through the Requests-Scala library for HTTP, and uJson for JSON processing. Both of these are available on Maven Central for you to use with any version of Scala:
// SBT
"com.lihaoyi" %% "ujson" % "0.7.1"
"com.lihaoyi" %% "requests" % "0.1.8"
// Mill
ivy"com.lihaoyi::ujson:0.7.1"
ivy"com.lihaoyi::requests:0.1.8"
Both of these libraries also comes bundled with Ammonite, and can be used within the REPL and *.sc script files. This tutorial will focus more on walking through a concrete example; for deeper details on each library's syntax and functionality, go to their reference documentation:
To begin with, I will install Ammonite:
$ sudo sh -c '(echo "#!/usr/bin/env sh" && curl -L https://github.com/lihaoyi/Ammonite/releases/download/1.6.7/2.12-1.6.7) > /usr/local/bin/amm && chmod +x /usr/local/bin/amm'
And open the Ammonite REPL, using requests.<tab> and ujson.<tab> to see the list of available operations:
$ amm
Loading...
Welcome to the Ammonite Repl 1.6.7
(Scala 2.12.8 Java 11.0.2)
@ requests.<tab>
BaseSession Response autoDecompress options
Compress ResponseBlob compress persistCookies
...
@ ujson.<tab>
Arr IncompleteParseException StringRenderer
AstTransformer IndexedValue SyncParser
...
Once this is set up, we are ready to begin the tutorial.
To motivate this tutorial, lets start off with a example task: to migrate a set of Github Issues from one repository to another. While Github easily lets you pull the source code history and push it to a new repository, the issues and pull requests are not so easy to move over.
We may want to do this for a number of reasons: perhaps the original repository owner has gone missing, and the community wants to move development onto a new repository, but without losing the valuable discussions and context present in the existing issue tracker. Or perhaps we wish to change platforms entirely: when Github became popular many people migrated their issue tracker to Github from places like JIRA or Bitbucket. When the next big thing comes up in another few years, it's not unthinkable that we might want to migrate their issue tracker off of Github!
For now, let us stick with a simple case: we want to perform a one-off, one-way migration of Github issues from one existing Github repo:
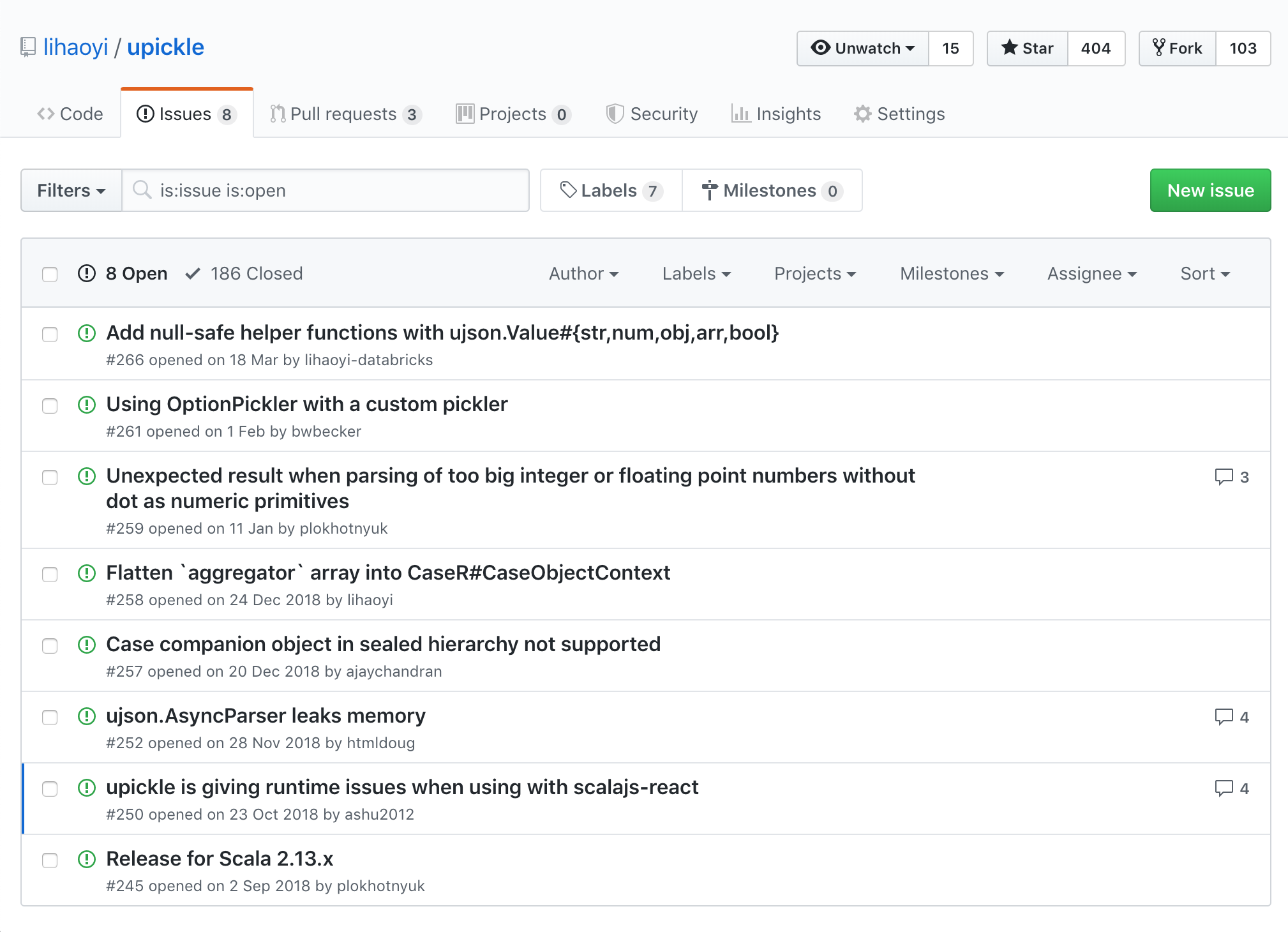
To a brand-new Github repo:
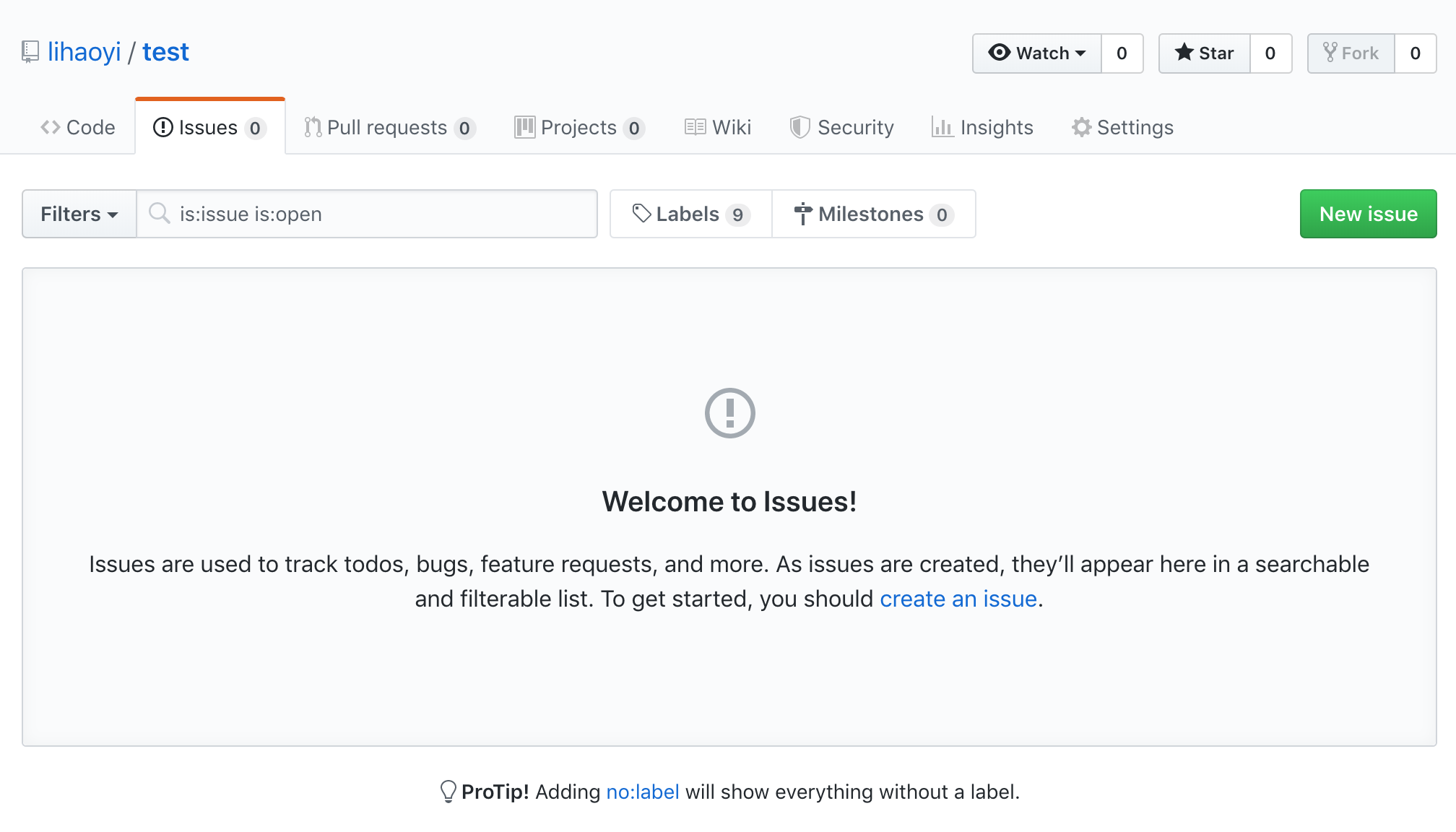
To limit the scope of the tutorial, we will only be copying over issues and comments, without consideration for other metadata like open/closed status, milestones, labels, and so on. Extending this tutorial to handle those cases is left as an exercise to the reader.
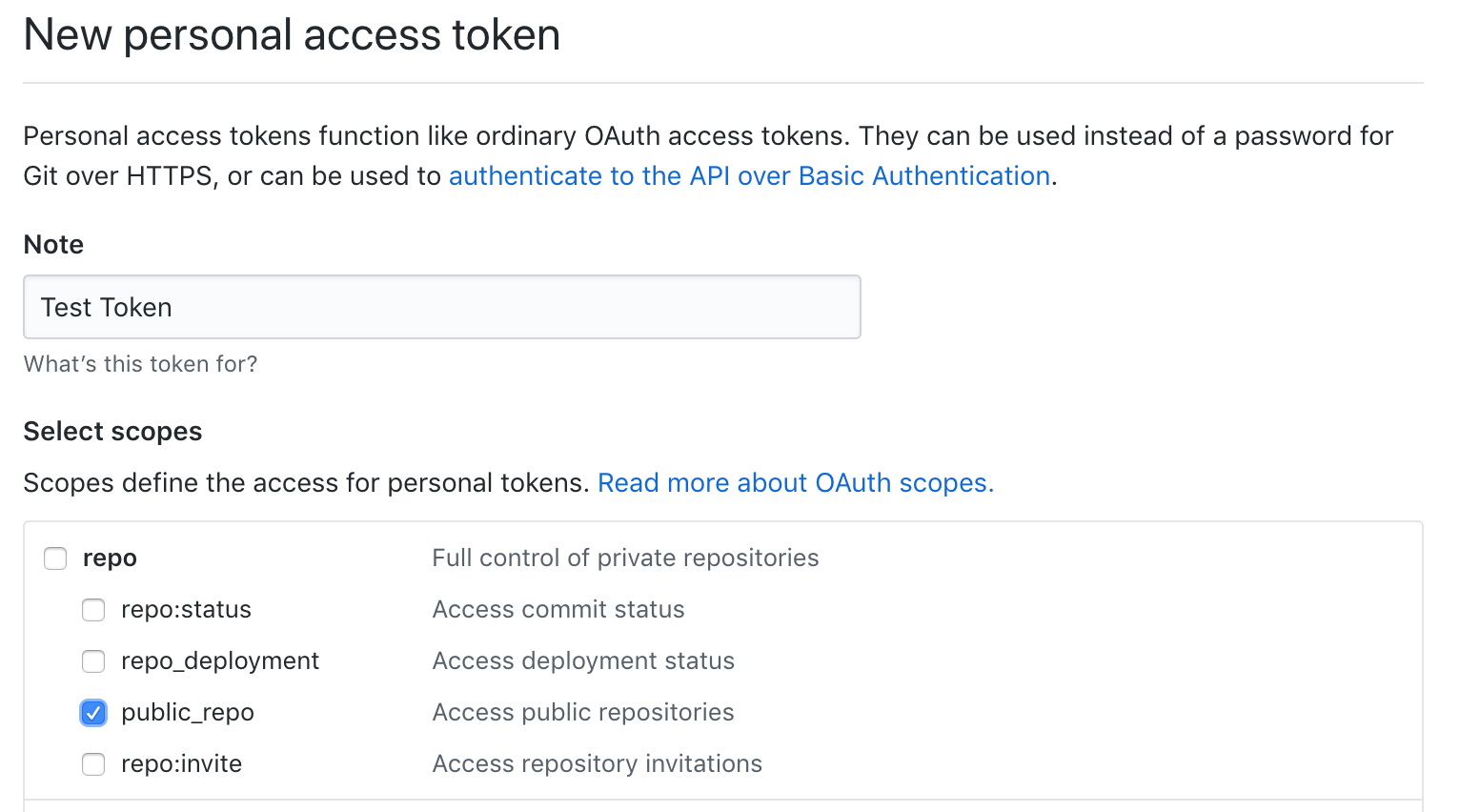
To begin with, we need to get an access token that gives our code read/write access to Github's data on our own repositories. The easiest way for a one-off project like this is to use a Personal Access Token, that you can create at:
Make sure you tick "public repositories" when you create your token:
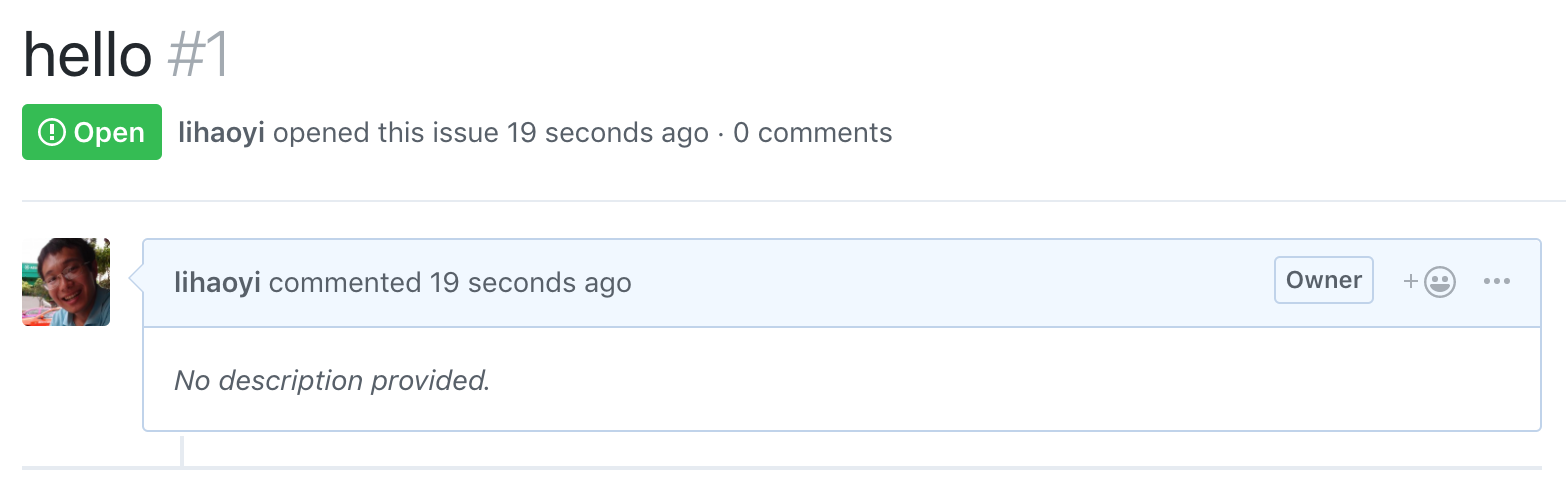
To test out this new token, we can make a simple test request to the create issue endpoint:
@ requests.post(
"https://api.github.com/repos/lihaoyi/test/issues",
data = ujson.Obj("title" -> "hello").render(),
headers = Map(
"Authorization" -> "token 1234567890abcdef1234567890abcdef",
"Content-Type" -> "application/json"
)
)
res56: requests.Response = Response(
"https://api.github.com/repos/lihaoyi/test/issues",
201,
"Created",
...
Going to the issues page, we can see our new issue has been created:
We can also try creating a comment, using:
@ requests.post(
"https://api.github.com/repos/lihaoyi/test/issues/1/comments",
data = ujson.Obj("body" -> "world").render(),
headers = Map(
"Authorization" -> "token 1234567890abcdef1234567890abcdef",
"Content-Type" -> "application/json"
)
)
res57: requests.Response = Response(
"https://api.github.com/repos/lihaoyi/test/issues/1/comments",
201,
"Created",
And open up the issue in the UI to see that the comment has been created:
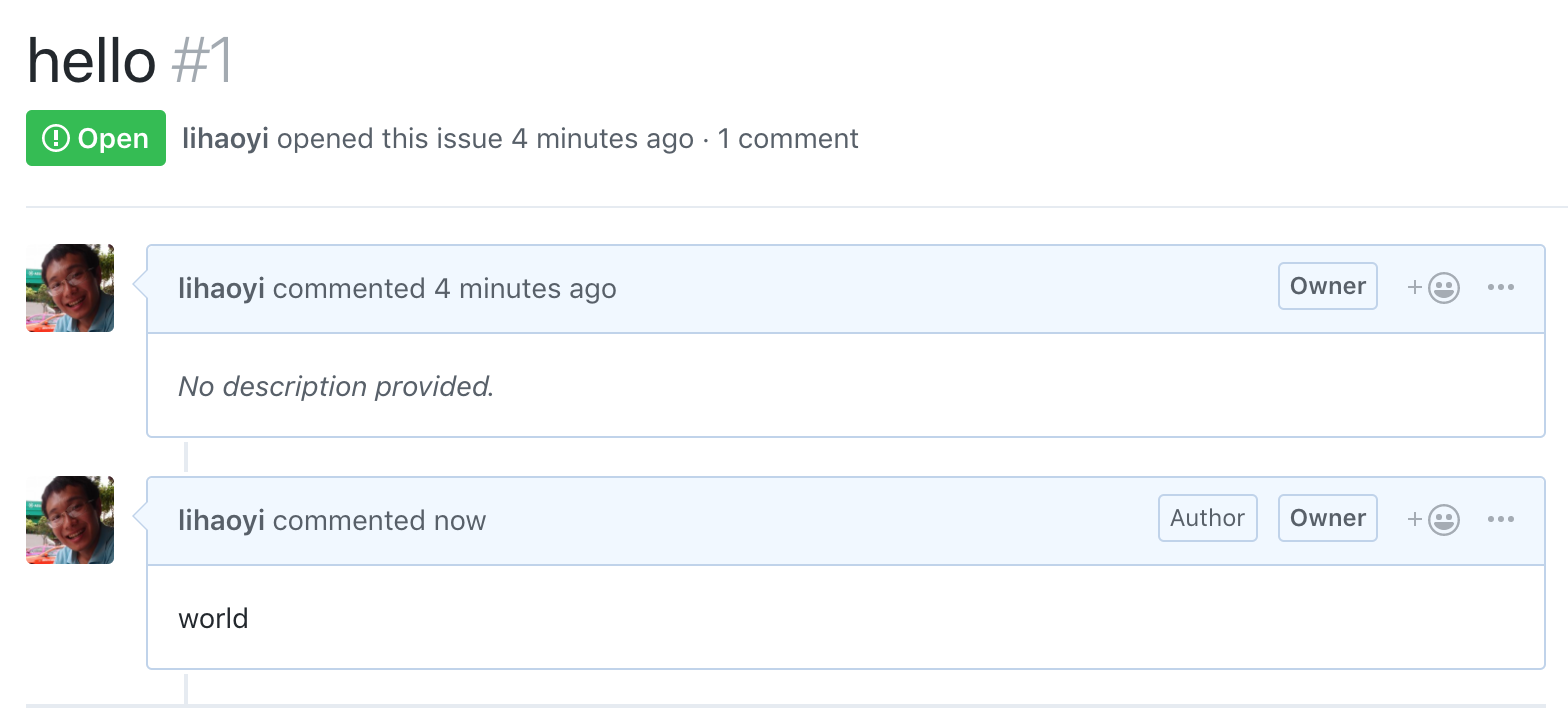
Now that we have basic read/write access working, we can use it to start with the more interesting parts of our migration.
Github provides a public JSON API to list the issues within a single repository:
This tells us that we can simply make a HTTP request in the following format:
GET /repos/:owner/:repo/issues
In order to fetch the issues for a particular repository.
Many parameters can be passed in to filter the returned list: by milestone, state, assignee, creator, mentioned, labels, etc.. However, for now we just want to get a listing of all issues (to duplicate to the new repository), we just need to make sure we set state=all to fetch all issues, both open and closed.
The documentation tells us we can expect a JSON response in the following format:
[
{
"id": 1,
"number": 1347,
"state": "open",
"title": "Found a bug",
"body": "I'm having a problem with this.",
"user": {
"login": "octocat",
"id": 1,
"node_id": "MDQ6VXNlcjE=",
"gravatar_id": "",
"type": "User",
"site_admin": false
},
"labels": [
{
"id": 208045946,
"name": "bug",
"description": "Something isn't working",
"color": "f29513",
"default": true
}
],
"assignee": {
"login": "octocat",
"id": 1,
"type": "User",
"site_admin": false
},
"assignees": [
{
"login": "octocat",
"id": 1,
"node_id": "MDQ6VXNlcjE=",
"type": "User",
"site_admin": false
}
],
"milestone": {
"id": 1002604,
"number": 1,
"state": "open",
"title": "v1.0",
"description": "Tracking milestone for version 1.0",
"creator": {
"login": "octocat",
"id": 1,
"type": "User",
"site_admin": false
},
"open_issues": 4,
"closed_issues": 8,
"created_at": "2011-04-10T20:09:31Z",
"updated_at": "2014-03-03T18:58:10Z",
"closed_at": "2013-02-12T13:22:01Z",
"due_on": "2012-10-09T23:39:01Z"
},
"locked": true,
"active_lock_reason": "too heated",
"comments": 0,
"closed_at": null,
"created_at": "2011-04-22T13:33:48Z",
"updated_at": "2011-04-22T13:33:48Z"
}
]
I have omitted a lot of repetitive fields for brevity. Nevertheless, this gives us a good idea of what we can expect: each issue has an ID, a state, a title, a body, and other metadata: creator, labels, assignees, milestone, and so on.
To access this data programmatically, we can use Requests-Scala to make a HTTP GET request to this API endpoint, to the lihaoyi/upickle module:
@ val resp = requests.get("https://api.github.com/repos/lihaoyi/mill/issues?state=all")
resp: requests.Response = Response(
"https://api.github.com/repos/lihaoyi/mill/issues",
200,
"OK",
Map(
"etag" -> ArrayBuffer("W/\"ce28c0ec24e755bfd0a536d0d701a81b\""),
...
And see the JSON string returned by the endpoint:
@ resp.text
res2: String = "[{\"url\":\"https://api.github.com/repos/lihaoyi/mill/issues/620\",...
To parse this JSON string into a JSON structure, we can use the ujson.read method:
@ val parsed = ujson.read(resp.text)
parsed: ujson.Value.Value = Arr(
ArrayBuffer(
Obj(
Map(
"url" -> Str("https://api.github.com/repos/lihaoyi/mill/issues/620"),
"repository_url" -> Str("https://api.github.com/repos/lihaoyi/mill"),
This lets us easily traverse the structure, or pretty-print it in a reasonable way:
@ println(parsed.render(indent = 4))
[
{
"id": 449398451,
"number": 620,
"title": "Issue with custom repositories when trying to use Scoverage",
"user": {
"login": "jacarey",
"id": 6933549,
...
As you can see, we have the raw JSON data from Github in a reasonable format that we can work with. The next step would be to analyze the data and extract the bits of information we care about.
The first thing to notice is that returned issues list is only 30 items long:
@ parsed.arr.length
res10: Int = 30
This seems incomplete, since we can clearly see that the lihaoyi/upickle repository has 8 open issues and 186 closed issues. On a closer reading of the documentation, we find out that this 30-item cutoff is due to pagination:
Requests that return multiple items will be paginated to 30 items by default. You can specify further pages with the ?page parameter. For some resources, you can also set a custom page size up to 100 with the ?per_page parameter. Note that for technical reasons not all endpoints respect the ?per_page parameter, see events for example.
In order to fetch all the items, we have to pass a ?page parameter to fetch subsequent pages: ?page=1, ?page=2, ?page=3, and so on. We can stop when there are no more pages to fetch, confident we have fetched all the data.
We can do that with a simple while loop:
@ {
var done = false
var page = 1
val responses = collection.mutable.Buffer.empty[ujson.Value]
while(!done){
println("page " + page + "...")
val resp = requests.get(
"https://api.github.com/repos/lihaoyi/upickle/issues?state=all&page=" + page
)
val parsed = ujson.read(resp.text).arr
if (parsed.length == 0) done = true
else responses.appendAll(parsed)
page += 1
}
}
page 1.
page 1...
page 2...
page 3...
page 4...
page 5...
page 6...
page 7...
page 8...
page 9...
page 10...
page 11...
Here, we parse each JSON response, cast it to a JSON array via .arr, and then check if the array has issues. If there's issues, we append all those issues to a responses buffer. If it's empty, that means we're done. We can verify we got all the issues we want by running:
@ responses.length
res18: Int = 272
Which matches what we would expect, with 8 open issues, 186 closed issues, 3 open pull requests, and 75 closed pull requests adding up to 272 issues in total.
Github by default treats issues and pull requests pretty similarly, but for the purpose of this exercise, let us assume we only want to copy over the issues. We'll also assume we don't need all the information on each issue: just the title, description, original author, and the text/author of each of the comments. That should be enough to preserve historical context and discussion around each issue.
A quick inspection shows that the JSON objects with the pull_request key represent pull requests, while those without represent issues. We can simply filter those out:
@ val issueResponses = responses.filter(!_.obj.contains("pull_request"))
@ issueResponses.length
res24: Int = 194
For each issue, we can easily pick out the number, title, body, and author:
@ val issueData = for(issue <- issueResponses) yield (
issue("number").num.toInt,
issue("title").str,
issue("body").str,
issue("user")("login").str
)
issueData: collection.mutable.Buffer[(Int, String, String, String)] = ArrayBuffer(
(
272,
"Custom pickling for sealed hierarchies",
"""Citing the manual, "sealed hierarchies are serialized as tagged values, the serialized object tagged with the full name of the instance's class". It works like this:
...
Now, we have the metadata around each top-level issue. However, one piece of information is still missing, and doesn't seem to appear at all in these responses: where are the issue comments?
It turns out that Github has a separate HTTP JSON API endpoint for fetching the comments of an issue:
Since there may be more than 30 comments, we need to paginate through the list-comments endpoint the same way we paginated through the list-issues endpoint:
@ {
var done = false
var page = 1
val comments = collection.mutable.Buffer.empty[ujson.Value]
while(!done){
println("page " + page + "...")
val resp = requests.get(
"https://api.github.com/repos/lihaoyi/upickle/issues/comments?page=" + page
)
val parsed = ujson.read(resp.text).arr
if (parsed.length == 0) done = true
else responses.appendAll(parsed)
page += 1
}
}
We can inspect the individual entries to see that we got what we want:
@ println(comments(0).render(indent = 4))
{
"url": "https://api.github.com/repos/lihaoyi/upickle/issues/comments/46443901",
"html_url": "https://github.com/lihaoyi/upickle/issues/1#issuecomment-46443901",
"issue_url": "https://api.github.com/repos/lihaoyi/upickle/issues/1",
"id": 46443901,
"user": {
"login": "lihaoyi",
"id": 934140,
"type": "User",
"site_admin": false
},
"created_at": "2014-06-18T14:38:49Z",
"updated_at": "2014-06-18T14:38:49Z",
"author_association": "OWNER",
"body": "Oops, fixed it in trunk, so it'll be fixed next time I publish\n"
}
From this data, it's quite easy to extract the issue each comment is tied to, along with the author and body text:
@ val commentData = for(comment <- comments) yield (
comment("issue_url")
.str
.stripPrefix("https://api.github.com/repos/lihaoyi/upickle/issues/")
.toInt,
comment("user")("login").str,
comment("body").str
)
commentData: collection.mutable.Buffer[(Int, String, String)] = ArrayBuffer(
(
1,
"lihaoyi",
"""Oops, fixed it in trunk, so it'll be fixed next time I publish
"""
),
(
2,
"lihaoyi",
"""Was a mistake, just published it, will show up on maven central eventually... Sorry!
"""
),
...
Now that we've got all the data from the old repository lihaoyi/upickle, and have the ability to post issues and comments to the new repository lihaoyi/test, it's time to do the migration!
We want:
One new issue per old issue, with the same title and description, with the old issue's Author and ID as part of the new issue's description
One new comment per old comment, with the same body, and the old comment's author included.
Creating a new issue per old issue is as simple as looping over the issueDate we accumulated earlier, and calling the create-issue endpoint once per issue we want to create with the relevant title and body:
@ for((number, title, body, user) <- issueData.sortBy(_._1)){
println(s"Creating issue $number")
val resp = requests.post(
"https://api.github.com/repos/lihaoyi/test/issues",
data = ujson.Obj(
"title" -> title,
"body" -> s"$body\nID: $number\nOriginal Author: $user"
).render(),
headers = Map(
"Authorization" -> "token 1234567890abcdef1234567890abcdef",
"Content-Type" -> "application/json"
)
)
println(resp.statusCode)
}
Creating issue 272
Creating issue 271
Creating issue 269
...
Creating issue 4
Creating issue 3
Creating issue 2
Creating issue 1
This creates all the issues we want:
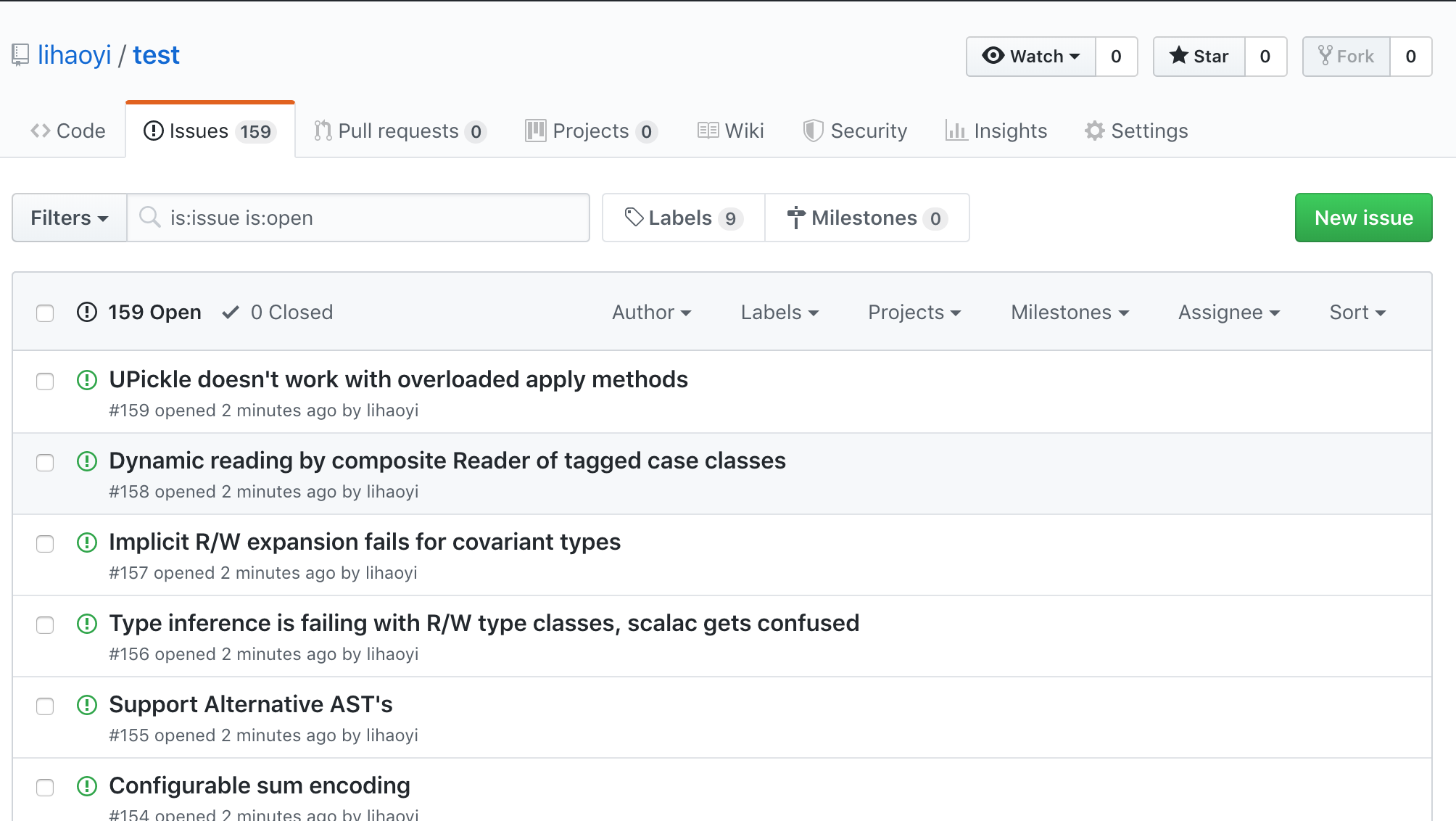
Creating comments is similar: we loop over all the old comments and post a new comment to the relevant issue. There's one subtlety: since we're not copying over pull requests, the old and new issue numbers might differ. This is straightforwardly solved by pre-computing a oldNewIssueNumberMap that allows us to map from the old issue IDs to the new issue IDs before copying each comment to its respective new issue:
@ val oldNewIssueNumberMap = issueData.sortBy(_._1).map(_._1).zipWithIndex.toMap.map{case (k, v) => (k, v + 1)}
oldNewIssueNumberMap: Map[Int, Int] = Map(
101 -> 118,
88 -> 127,
170 -> 66,
115 -> 107,
217 -> 35,
120 -> 103,
269 -> 2,
202 -> 46,
56 -> 151,
...
@ for((issueId, user, body) <- commentData){
if (oldNewIssueNumberMap.contains(issueId)) {
println(s"Commenting on issue old_id=$issueId new_id=${oldNewIssueNumberMap(issueId)}")
val resp = requests.post(
s"https://api.github.com/repos/lihaoyi/test/issues/${oldNewIssueNumberMap(issueId)}/comments",
data = ujson.Obj("body" -> s"$body\nOriginal Author:$user").render(),
headers = Map(
"Authorization" -> "token 1234567890abcdef1234567890abcdef",
"Content-Type" -> "application/json"
)
)
println(resp.statusCode)
}
}
Commenting on issue old_id=1 new_id=1
201
Commenting on issue old_id=2 new_id=2
201
Commenting on issue old_id=3 new_id=3
201
...
Commenting on issue old_id=39 new_id=33
201
Commenting on issue old_id=271 new_id=193
201
Commenting on issue old_id=272 new_id=194
201
Now, we can see that all our issues have been populated with their respective comments:
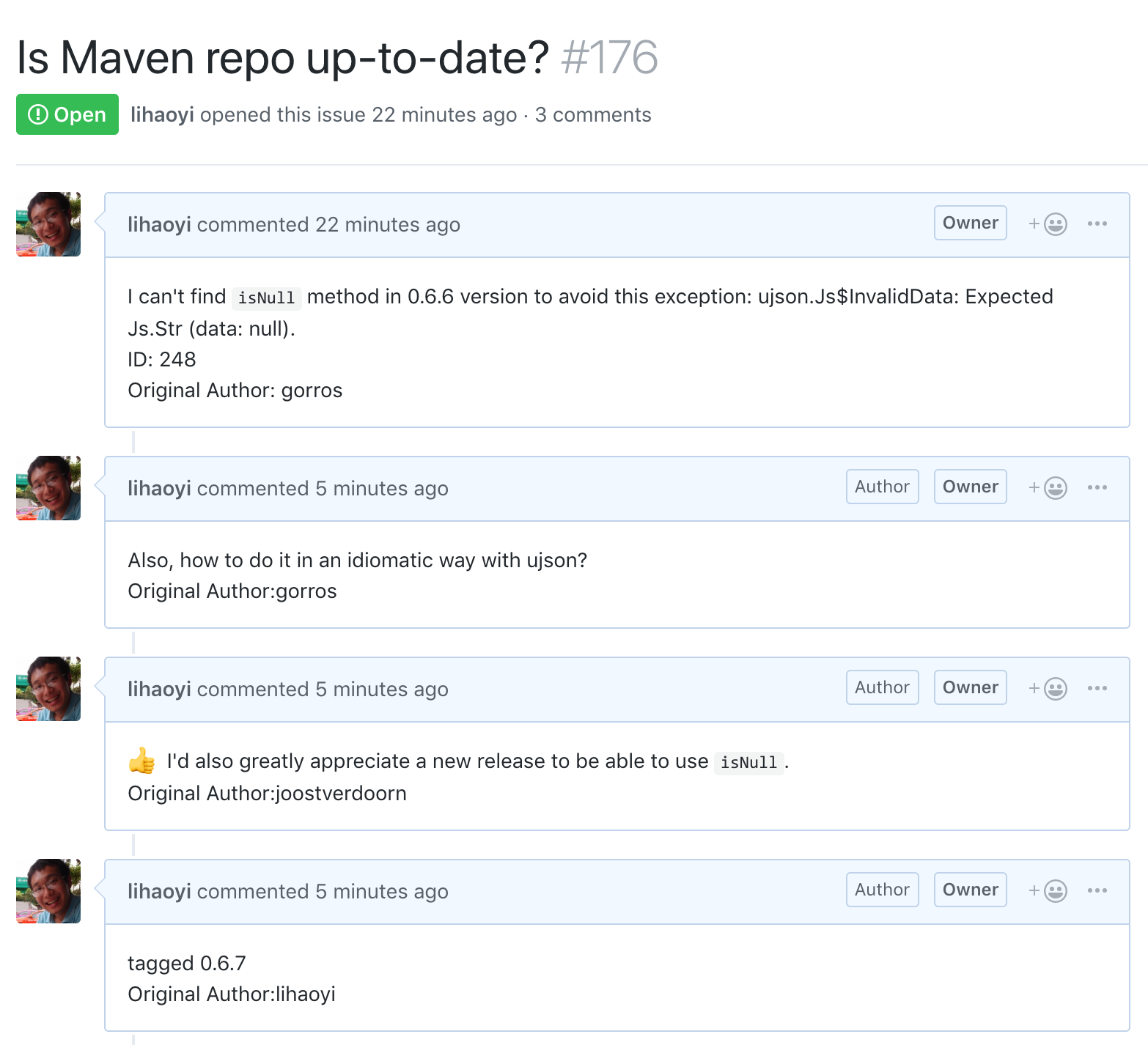
And we're done!
To wrap up, here's all the code for our Github Issue Migrator, all in one place:
val issueResponses = {
var done = false
var page = 1
val responses = collection.mutable.Buffer.empty[ujson.Value]
while(!done){
println("page " + page + "...")
val resp = requests.get(
"https://api.github.com/repos/lihaoyi/upickle/issues?state=all&page=" + page,
headers = Map("Authorization" -> "token 1234567890abcdef1234567890abcdef")
)
val parsed = ujson.read(resp.text).arr
if (parsed.length == 0) done = true
else responses.appendAll(parsed)
page += 1
}
responses.filter(!_.obj.contains("pull_request"))
}
val issueData = for(issue <- issueResponses) yield (
issue("number").num.toInt,
issue("title").str,
issue("body").str,
issue("user")("login").str
)
val comments = {
var done = false
var page = 1
val responses = collection.mutable.Buffer.empty[ujson.Value]
while(!done){
println("page " + page + "...")
val resp = requests.get(
"https://api.github.com/repos/lihaoyi/upickle/issues/comments?page=" + page,
headers = Map("Authorization" -> "token 1234567890abcdef1234567890abcdef")
)
val parsed = ujson.read(resp.text).arr
if (parsed.length == 0) done = true
else responses.appendAll(parsed)
page += 1
}
responses
}
val commentData = for(comment <- comments) yield (
comment("issue_url")
.str
.stripPrefix("https://api.github.com/repos/lihaoyi/upickle/issues/")
.toInt,
comment("user")("login").str,
comment("body").str
)
for((number, title, body, user) <- issueData.sortBy(_._1)){
println(s"Creating issue $number")
val resp = requests.post(
"https://api.github.com/repos/lihaoyi/test/issues",
data = ujson.Obj(
"title" -> title,
"body" -> s"$body\nID: $number\nOriginal Author: $user"
).render(),
headers = Map(
"Authorization" -> "token 1234567890abcdef1234567890abcdef",
"Content-Type" -> "application/json"
)
)
println(resp.statusCode)
}
val oldNewIssueNumberMap = issueData.sortBy(_._1).map(_._1).zipWithIndex.toMap.map{case (k, v) => (k, v + 1)}
for((issueId, user, body) <- commentData){
if (oldNewIssueNumberMap.contains(issueId)) {
println(s"Commenting on issue old_id=$issueId new_id=${oldNewIssueNumberMap(issueId)}")
val resp = requests.post(
s"https://api.github.com/repos/lihaoyi/test/issues/${oldNewIssueNumberMap(issueId)}/comments",
data = ujson.Obj("body" -> s"$body\nOriginal Author:$user").render(),
headers = Map(
"Authorization" -> "token 1234567890abcdef1234567890abcdef",
"Content-Type" -> "application/json"
)
)
println(resp.statusCode)
}
}
This tutorial only covers the basics of writing a Github Issue Migrator, and skips over features like:
Copying the issue open/closed state using their Edit an Issue endpoint and requests.patch
Copy other metadata like labels, milestones, or assignees, or lock-status
Migrating pull requests
Extending the code given in this tutorial to support those use cases is left as an exercise for the reader.
Working with HTTP JSON APIs in Scala is simple and straightforward; you can easily use requests.get posts to access the data you need, ujson to manipulate the JSON payloads, and requests.post to send commands back up to the third party service.
This tutorial only covers copying over issues and comments, without consideration for other metadata like open/closed status, milestones, labels, and so on. Handle those additional pieces of data and functionality is left as an exercise to the reader.
About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming