com.lihaoyi Scala: Executable Pseudocode that's Easy, Boring, and Fast
Python has a reputation as "Executable Pseudocode": code that fits just as easily on a whiteboard during a discussion, as it does in a codebase deploying to production. Scala is a language that can be just as concise a pseudocode as Python, and arguably better at the "executable" part: faster, safer, and with better tooling. This blog post will explore how the Scala libraries from the com.lihaoyi ecosystem allows the use of Scala as Executable Pseudocode, due to their unique design philosophy that stands out amongst the rest of the Scala ecosystem.

About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming
This blog post will introduce the com.lihaoyi tools and libraries, explore the design principles involved and how they manifest themselves in various tools and libraries, and finally do a deep dive into the Mill build tool to examine how it uses these principles to provide a user experience far more intuitive than any other build tool on the market.
This is the companion post to the conference talk (of the same name) given at Scaladays Seattle, 7 June 2023:
What is com.lihaoyi?
The com.lihaoyi Scala ecosystem is a set of tools and libraries I've slowly built up over the past decade. A sampling of the most notable ones are listed below, along with the year each one was first published:
- (2012) Scalatags, HTML Generation Library
- (2014) FastParse: Fast Parser Combinators
- (2014) uTest: Minimal Testing Library
- (2014) uPickle: JSON & Binary Serialization Library
- (2015) Ammonite: Fancy Scala REPL
- (2016) Sourcecode: Implicit source metadata: file-names, line numbers, etc.
- (2017) Mill: Better Scala Build Tool
- (2017) PPrint: Pretty-Printing Library
- (2018) OS-Lib: Filesystem/Subprocess Library
- (2018) Requests-Scala: HTTP Request Library
- (2018) Cask: HTTP Micro-Framework
- (2020) MainArgs: CLI Argument Parsing Library
These libraries, originally on my personal Github account, are now under a com-lihaoyi Github organization with a handful of maintainers. In terms of popularity, they get around 18 million downloads a month from Maven Central: probably less than some other more famous Scala frameworks, but an indication of real usage out in the wild beyond just myself.
The com.lihaoyi ecosystem is largely self contained. The libraries depend on each other, but do not have dependencies on other large Scala frameworks like Akka, Cats, ZIO, etc. The style of code in com.lihaoyi is also very different from many of the other large frameworks in the Scala ecosystem.
In one line, the core design principles of the com.lihaoyi ecosystem can be summarized as:
Executable Scala Pseudocode that's Easy, Boring, and Fast
Let's dig into what exactly that means
Executable Scala Pseudocode
Scala has always been known as a concise, flexible language. And yet it is Python that is normally thought of as "Executable Pseudocode", not Scala. It turns out that while Scala the language can be concise and intuitive, Scala the ecosystem often is not. This section will examine two case studies, and demonstrate how the com.lihaoyi libraries make significant improvements over the Scala status quo.
Executable Scala Pseudocode: HTTP Requests
Imagine for a moment you are in an programming interview. You are in a small room with someone who just asked you to write a web crawler or a Github issue migrator or some other such programming challenge, on a whiteboard.
You’ve sketched out the skeleton of your solution, and it’s time to make a HTTP request. It’s just a whiteboard, so it doesn’t need to actually run, but you need to write pseudocode: something that makes the most sense both to you and to the interviewer. What do you write?
Traditionally, performing such a HTTP request using Scala would look something like this:
import akka.actor.typed.ActorSystem
import akka.actor.typed.scaladsl.Behaviors
import akka.http.scaladsl.Http
import akka.http.scaladsl.model._
import scala.util.{ Failure, Success }
implicit val system = ActorSystem(Behaviors.empty, "SingleRequest")
implicit val executionContext = system.executionContext
val responseFuture = Http()
.singleRequest(HttpRequest(uri = "http://akka.io"))
responseFuture.onComplete {
case Success(res) => println(res)
case Failure(_) => sys.error("something wrong")
}
This is a minimal example using the popular Akka-HTTP client. You start off importing an ActorSystem, three things from two different kinds of DSL, and some util stuff. You then instantiate the ActorSystem and configure it's Behavior and extract it's executionContext. Finally you instantiate the HttpRequest object, and send it over the network using Http().singleRequest. But you're not done yet! You still need to use responseFuture.onComplete, pattern-match on Success and Failure, and only then can you get access to the HTTP response to actually do things with it.
This is not "Executable Pseudocode". You would not write this on a whiteboard.
Almost all this stuff is irrelevant to the initial problem at hand. Sure, later on you may want to tweak the executionContexts, properly size the threadpools, configure the ActorSystem appropriately for a production deployment. But all that stuff can be done later. If you were at a whiteboard, scribbling on a notebook, or even throwing together a prototype, none of those are things you want to be thinking about until truly necessary. In fact, there are plenty of production applications where those things never become necessary!
If you were like me, standing at a whiteboard, you would write something like this:
val res = requests.get("https://akka.io")
println(res)
You need to make a get request, so you call requests.get. HTTP requests need a URL, so you pass it. You then get a result to use. End of story.
This is pseudocode. It is also executable code, using the Requests-Scala library. That's what makes it Executable Pseudocode!
Executable Pseudocode: CLI Arguments
Imagine you just hired a new intern, and their summer project is to write a small command line tool. You’re trying to explain what this tool is going to do, and what flags it will take, on a piece of paper at your intern’s desk. What do you write on this piece of paper?
Scala doesn't provide CLI argument parsing built-in. Using an third-party library like Scopt, you would have to write something like this:
case class Config(foo: String = null,
num: Int = 2,
bool: Boolean = false)
val builder = OParser.builder[Config]
val parser1 = {
import builder._
OParser.sequence(
programName("run"),
opt[String]("foo")
.required()
.action((x, c) => c.copy(foo = x)),
opt[Int]("num")
.action((x, c) => c.copy(num = x)),
opt[Unit]("bool")
.action((_, c) => c.copy(bool = true))
)
}
val parsed = OParser.parse(parser1, args, Config())
for(Config(foo, num, bool) <- parsed){
println(foo * num + " " + bool.value)
}
You'd start off by defining a Config class with the field names and types you expect the CLI tool to take. That part's fine.
But then you follow up by creating a builder that's a OParser.builder of the Config. And then define another lowercase-p parser (different from the first capital-P OParser) that imports the builder, and then uses the capital-P OParser again to do... a whole bunch of boilerplate that mostly duplicates what you already wrote in Config: repeating the types, parameter names, etc. Then you use the capital-P parser to parse the lowercase-p parser along with the arguments, and a dummy config value, to finally parse out the parsed values that you can finally use.
If you tried to explain to your summer intern what their intern-project CLI tool was meant to do in this way, you'd probably end up with a very confused intern! Try reading the above-paragraph out loud to see how crazy and confusing it sounds! And yet that's exactly what many Scala libraries look like.
One thing to note is that a lot of this complexity makes sense from a software engineering perspective. Error handling. Builder pattern. Composition over inheritance. Separation over concerns. These are all things that are crucial to the health of a codebase. But many of these things are "internal" concerns, relevant to the person implementing the CLI parsing library, and not relevant to the person using it. At least not when they're just getting started!
So if you were to write pseudocode on a piece of paper for your intern, what would you write? Perhaps something like this:
def run(foo: String, num: Int = 2, bool: Flag) = {
println(foo * num + " " + bool.value)
}
The main method of a CLI tool is just a method that takes arguments, so we write def, and list out the arguments it takes and their types. We then get to the body of the method, between the curly braces, and fill that in with pseudocode for what the CLI tool is meant to do. End of story.
It turns out, this is not too different from what the MainArgs library lets you do. Just slap on a @main annotation, pass in the real CLI arguments (an Array[String]) to some helper method, and we're done!
@main
def run(foo: String, num: Int = 2, bool: Flag) = {
println(foo * num + " " + bool.value)
}
def main(args: Array[String]): Unit = ParserForMethods(this).runOrExit(args)
$ ./example.jar --foo hello
hellohello false
$ ./example.jar --foo hello --num 3 --bool
hellohellohello true
$ ./example.jar --help
run
--foo <str>
--num <int>
--bool
This gives you a CLI entrypoint, argument parsing, error messages, help messages, and so on. You can flesh it out more if you'd like with top-level docs, per-param docs, etc., but it is already very usable. We just took the code you would have sketched on paper, annotated it, and it works. That's executable Pseudocode!
Concise Language with a Clunky Ecosystem
These examples perhaps highlight the traditional problem with Scala as Executable Pseudocode.
The language is fine. But the libraries have traditionally been verbose and clunky. So while snippets of pure-scala on slides look great defining a linked list or fibonacci function or something, any Scala that actually has to do something is just as ugly and verbose as Java code!
People like making fun of Java for being verbose, but Java's ArgParse4j would actually look not much uglier than the Scopt snippet above, and Java's Apache HTTP Client would look not much more verbose than the Akka HTTP snippet. These Scala libraries are a different style of ugly from Java, with a different set of language features and design patterns making them verbose. But they are unnecessarily ugly and verbose all the same. Scala needs to do better.
com.lihaoyi Scala libraries
com.lihaoyi libraries all look very different from traditional Scala libraries, and they look very similar to each other:
// mainargs
@mainargs.main
def run(foo: String, num: Int = 2, bool: Flag) = {
println(foo * num + " " + bool.value)
}
// cask
@cask.get("/user/:userName")
def showUserProfile(userName: String) = {
s"User $userName"
}
// uPickle
upickle.default.write(Seq(1, 2, 3))
// requests
val resp = requests.get("http://akka.io")
// os-lib
os.proc("grep", "Data")
.call(
stdin = resp,
stdout = os.pwd / "Out.txt"
)
// Mill
def lineCount = T{
allSourceFiles()
.map(f => os.read.lines(f.path).size)
.sum
}
By and large, they revolve around Scala method defs and Scala method calls, with a sprinkling of annotations for customization. These all match more or less how a developer would think of the problem:
- A main method taking CLI arguments is a method that takes parameters.
- HTTP get and post endpoints are methods that take parameters.
- Making HTTP requests or subprocess operations are just method calls that you pass parameters
Note what we don’t see here: DSLs, implicits, inheritance, builder patterns, config objects, wrappers, adapters, registries, visitors, etc. Even imports are minimized!
That’s not to say that these things aren’t used: all of these libraries make heavy use of design patterns in their implementation. And they do allow you to control things in more details when your requirements are less trivial. A user who needs to configure their HTTP request using requests.get can pass in one of many optional parameters below, and the library offers other mechanisms to support more advanced use cases.
// siganture of requests.get.apply
def apply(url: String,
auth: RequestAuth = sess.auth,
params: Iterable[(String, String)] = Nil,
headers: Iterable[(String, String)] = Nil,
data: RequestBlob = RequestBlob.EmptyRequestBlob,
readTimeout: Int = sess.readTimeout,
connectTimeout: Int = sess.connectTimeout,
proxy: (String, Int) = sess.proxy,
cert: Cert = sess.cert,
sslContext: SSLContext = sess.sslContext,
cookies: Map[String, HttpCookie] = Map(),
cookieValues: Map[String, String] = Map(),
maxRedirects: Int = sess.maxRedirects,
verifySslCerts: Boolean = sess.verifySslCerts,
autoDecompress: Boolean = sess.autoDecompress,
compress: Compress = sess.compress,
keepAlive: Boolean = true,
check: Boolean = sess.check,
chunkedUpload: Boolean = sess.chunkedUpload): Response
Although there are a ton of things you can tweak and configure, a typical user gets reasonable defaults and a simple API, only needing to complicate their code when the need for the additional flexibility arises. Advanced customization is available, but not forced upon those who do not need it. The user's code can thus remain only as complicated as the task that they need to do, with trivial tasks resulting in code trivial enough to write out by hand on a whiteboard.
That's how the com.lihaoyi libraries aim for Executable pseudocode. Next, let's talk about Easy.
Easy, Not Simple
"Simple Not Easy" is a meme that originated in a talk by the author of the Clojure programming language. It claims that "Simplicity" means that a system from top-to-bottom is made of a small number of orthogonal concepts, while "Easy" is more about familiarity, about polish, and molding your product closely to a specific use case.
Not everything that is Simple is Easy, and not everything that is Easy is Simple.
Some people say Scala is already very Simple. Martin Odersky likes saying that Scala has a very small grammar, and in a way he’s right. Scala does have a relatively small number of orthogonal features:
- Methods, Arrays, Sets, Dictionaries, Factories, Lambdas, copy-constructors, are all functions called via
foo(bar)
- (almost) Everything - method bodies, statements, expressions,
if/else, for-loops, try/catch - is an expression
- Extension methods, context parameters, auto-constructors, typeclasses, dependency injection, are all just
implicits
Even compared to other similar modern hybrid languages like Kotlin/Swift/F#, Scala does indeed have a small number of orthogonal concepts that can be composed together. It’s already Simple. What Scala is missing is the Easy.
FastParse: Easy, not Simple
Consider the following FastParse code, a snippet from the example JSON parser:
def string[$: P] = P(space ~ "\"" ~/ (strChars | escape).rep.! ~ "\"")
.map(Js.Str(_))
def array[$: P] = P("[" ~/ jsonExpr.rep(sep = ","./) ~ space ~ "]")
.map(Js.Arr(_: _*))
def pair[$: P] = P(string.map(_.value) ~/ ":" ~/ jsonExpr)
def obj[$: P] = P("{" ~/ pair.rep(sep = ","./) ~ space ~ "}")
.map(Js.Obj(_: _*))
It might look a bit cryptic at first, but it’s not that different from other Scala parser combinator libraries, e.g. the one that used to be in the standard library. string is made of a quote followed by string characters followed by a closing quote. array is made of an open bracket followed by comma-separated expressions followed by a closing bracket. object is a open curly, followed by comma-separated key-value pairs (each a string, a colon, and a jsonExpr) followed by a closing curly. And so on.
There are some details involved: .!s to capture things, .maps to turn them into case classes, spaces are added to handle JSON that’s not minified. But overall it still closely matches how you would think of syntax of a language, in this case the syntax of the JSON language we want to parse.
Just by writing what’s effectively a language grammar, FastParse doesn’t just give you a high-performance parser, but it also gives you excellent error reporting for free. For example, if I forget an entry in my array and put a closing bracket after the comma, I immediately get an error message with the offset in the string, what characters it found, and what it was expecting to find.
@ fastparse.parse("""["1", "2", ]""", array(_))
Failure at index: 11, found: ..."]"
expected: (obj | array | string | true | false | null | number)
Simple parser definition. Good performance: ~300x faster than scala-parser-combinators, competitive with hand-written parsers. Good error messages, both for the parser author and the parser user. A wide variety of built-in debugging tools and techniques. Thorough documentation. That is exactly what someone parsing something wants. Using FastParse is Easy
But Fastparse is not Simple. Below is the data structure representing the internal workings of FastParse: the parsing, backtracking, error reporting, etc.
final class ParsingRun[+T](
val input: ParserInput,
val startIndex: Int,
val originalParser: ParsingRun[_] => ParsingRun[_],
val traceIndex: Int,
val instrument: Instrument,
// Mutable vars below:
var terminalMsgs: Msgs,
var aggregateMsgs: Msgs,
var shortMsg: Msgs,
var lastFailureMsg: Msgs,
var failureStack: List[(String, Int)],
var isSuccess: Boolean,
var logDepth: Int,
var index: Int,
var cut: Boolean,
var successValue: Any,
var verboseFailures: Boolean,
var noDropBuffer: Boolean,
val misc: collection.mutable.Map[Any, Any])
Dealing with mutable state is not simple. FastParse internally uses tons of mutable state! All the vars above are mutable. FastParse internals are not simple, and are actually really confusing, precisely due to all this mutable state. To top things off, all this is layered under a thick layer of Macros, implemented twice for Scala 2 and Scala 3. Far from being simple, the relatively-small Fastparse codebase is a real pain in the neck to work with internally.
However, this complexity is not for nothing: it is precisely this complexity that makes FastParse so much faster than the alternatives while providing such good error messages.
If FastParse went with a simpler functional programming style, it would have been much simpler to implement, but we'd easily be looking at an order of magnitude slowdown or more. That would mean more work for the person writing the parser: maybe they need to worry about parsing performance now, maybe they need to start caching things, maybe they need to rewrite the parser in some other framework when a prototype goes to production. Having FastParse be so fast makes their life easier by letting them avoid all of those worries.
FastParse is not Simple, but using FastParse is definitely Easy.
MainArgs: Easy, not Simple
Let's revisit the MainArgs example we saw earlier:
@main
def run(foo: String, num: Int = 2, bool: Flag) = {
println(foo * num + " " + bool.value)
}
def main(args: Array[String]): Unit = ParserForMethods(this).runOrExit(args)
We annotate a method with @main, call ParserForMethods.runOrExit, and that's it. Easy enough. But what's happening under the hood?
Under the hood, ParserForMethods is a macro that inspects the object it is given, looks up all the @main-annotated methods on it, and expands into the following code (slightly simplified):
ParserForMethods(
Seq(
MainData(
name = "run",
argSigs0 = Seq(
ArgSig[String](name = "foo", default = None),
ArgSig[Int](name = "num", default = Some(2)),
ArgSig[Flag](name = "bool", default = None),
),
invoke = {
case Seq(foo: String, num: Int, bool: Flag) =>
this.run(foo, num, bool)
}
)
)
).runOrExit(args)
As you can see, it’s a relatively verbose, but straightforward data structure: the name of the method, a list of ArgSigs with types and metadata for each parameter, an invoke callback which takes the parsed arguments and passes them to the actual run method the developer wants to execute. Then runOrExit uses the metadata to parse the Array[String] into a foo: String, num: Int, bool: Flag and passes them to the invoke callback.
If you take this generated code and compare it to the Scopt snippet we saw earlier, you'll find that they are just as complicated as each other. In fact, they're almost the exact same data structure!
Mainargs’ value is not being simpler than the alternative. It is about as simple as Scopt internally, with a layer of additional macro transformations that add complexity and make it less simple overall. The point of mainargs is to bundle up all this verbose data structure definition into a thin macro facade that does exactly what a user probably wants, using the "define a method taking typed arguments" syntax that all Scala developers would already be familiar with. That's how Mainargs aims to be Easy!
Boring
Next thing to discuss is Boring
Traditional Scala projects have always been very ambitious. Things like:
When compared to the com.lihaoyi projects, there's a stark different: the com.lihaoyi projects are boring!
- JSON/Binary Serialization
- HTTP Clients/Servers
- HTML Generation
- Parsing Strings
- Filesystem/Subprocess Operations
- Pretty-printing
- CLI Argument Parsing
- Build Tooling
While the traditional Scala projects are the kind you may give keynote conference presentations about, the com.lihaoyi projects are the kind you would add to your build file, use, and forget about. And that’s intentional!
Cathedrals
One way I like thinking about this is that traditional Scala projects have often been Cathedrals: huge efforts, aesthetically beautiful, doing amazing things nobody thought was possible.
But being a cathedral also has its downsides. If I want a small house to stay in, or a bridge, or a grain silo, having a huge cathedral is a poor fit. You also can’t mix two cathedrals together. And cathedrals often require significant ongoing maintenance by skilled craftsmen to keep things in shape.
That’s always been the problem with Scala: if you want super-high-concurrency low-latency distributed computation, then Akka is perfect. If you want to write pure-functional referentially-transparent code, then one of the FP frameworks is a great fit. If you want anything else... you're out of luck. And you can’t mix these options: you’re not going to use Akka in your SBT build definition, or use Cats-Effect in your Akka streams. And if the company supporting your framework runs out of VC money, or the individual supporting your framework gets burnt out, your cathedral may be in trouble.
Bricks
In contrast, the com.lihaoyi libraries aim to be bricks. Boring, uninteresting, but solid and reliable. And you’re meant to combine them together to build things, bricks don’t have an opinion on what you are building. Whether you’re building a house or a bridge or a grain silo, or even another cathedral, you can use bricks.
com.lihaoyi libraries are meant to be usable everywhere:
-
You can use Scalatags to render HTML in your personal blog generator, in your Akka/Play backend server, in HTTP4S, or in Scala.js.
-
You can use the Ammonite REPL to interactively work with your Akka cluster, your Cats code, your ZIO code, or even your legacy Java application.
-
You can use uPickle to serialize data in your Mill build file, your one-off research project, or your 10,000 QPS production API server.
com.lihaoyi libraries aim to be bricks. They don't care where they're used, or what framework or code style you're trying to fit them in. They're meant to be mix-and-matched. They require minimal maintenance, so much so that if the original maintainers go missing it would be easy enough to fork them and perform any necessary maintenance yourself. Rendering HTML or Parsing JSON isn't rocket science!
Fast
The last point to touch on, is "Fast". The com.lihaoyi ecosystems aim to be Fast.
Not the Fastest. There will always be someone willing to run one more profile, implement one more optimization, bash one more bit. But JVM performance is great. People build huge systems in Python and Ruby, that are reasonably snappy, despite the languages and runtimes being 1-2 orders of magnitude slower than bytecode running on the JVM. Apart from some core limitations like memory footprint and warmup time, Scala running on the JVM has no excuse to be slow
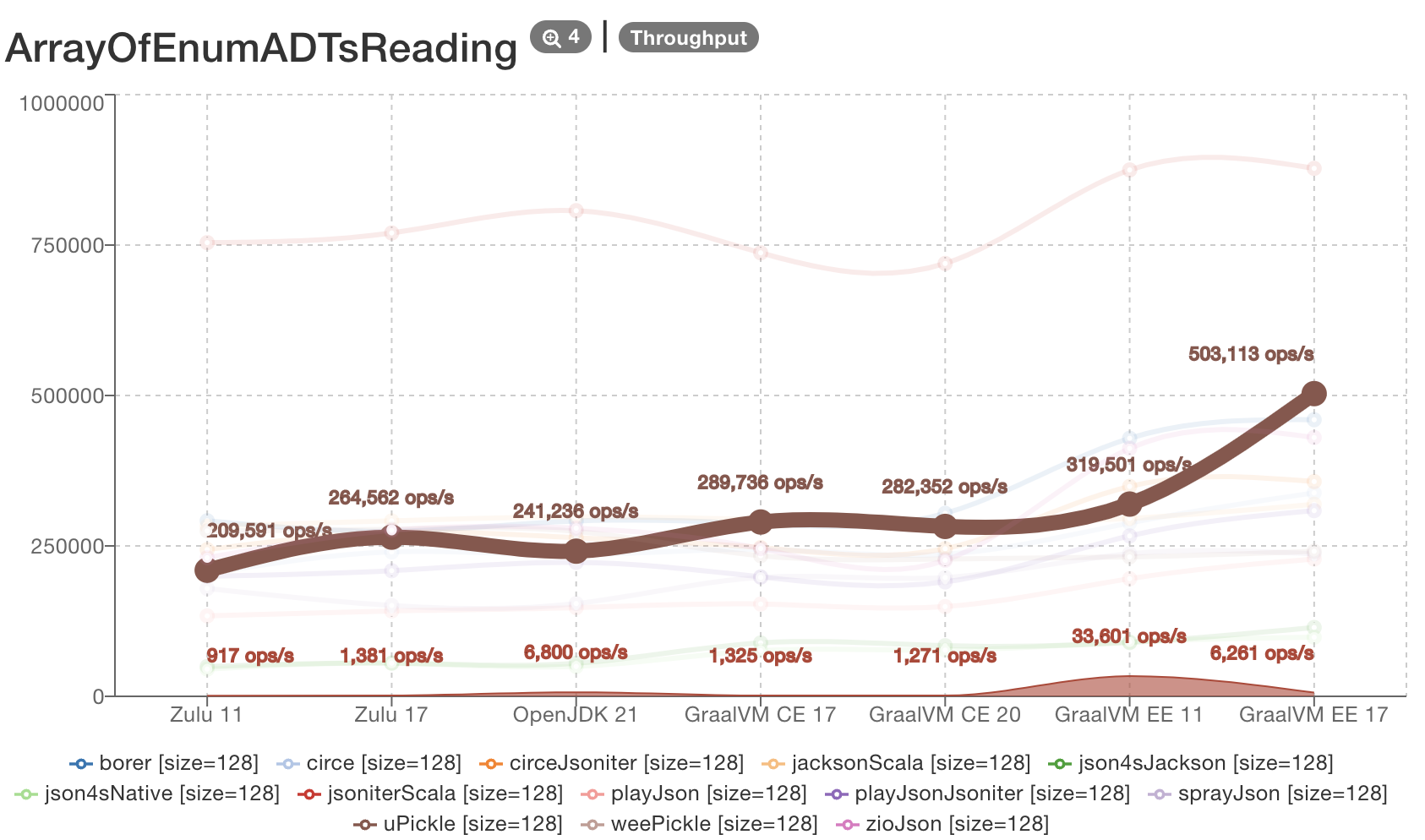
Here is a rough collection of benchmarks that illustrates this philosophy:
- uPickle’s rough performance (solid brown line). Not at the top of the benchmark, but definitely in the upper half among other JSON libraries
- The performance of Fastparse’s example JSON parser. It is competitive to hand-crafted hand-optimized parsers, even though it’s not the top. Notably, it’s over 150 times faster than the equivalent JSON parser written using Scala-Parser-Combinators. Which shows what can easily happen for libraries that do not care about performance at all
| JSON Parser |
Parses/60s |
| Circe |
332 |
| Play-JSON |
227 |
| FastParse Example JSON |
160 |
| Argonaut |
149 |
| JSON4S |
101 |
| Scala-Parser-Combinators |
0.9 |
- The performance of the Scalatags templating engine: a few times faster than scala-xml/twirl and 15-20 times faster than Scalate templates
| Template Engine |
Renders/60s |
| Scalatags |
7436041 |
| Scala-XML |
3794707 |
| Twirl |
1902274 |
| Scalate-Mustache |
500975 |
| Scalate-Jade |
396224 |
Some of these benchmarks are recent, while others are a bit out of date. But the point here is that while com.lihaoyi libraries are not top dog in terms of performance, they aim to perform pretty well, and generally do. Well enough that "the library is slow" is not going to be an problem in the systems you use them in
Having fast tools and libraries is good, even if you do not care about performance. In fact, having fast building blocks is often what lets you not care about performance!
If your building blocks are slow, performance becomes a problem, and you have to spend time on fancy algorithms, optimizations, caching, incremental computation, parallelism, distribution. Maybe you need to swap out your std lib priority queue with a hand-rolled Van Em Boas data structure from CLRS. This adds a whole bunch of cool, challenging, interesting work that is exactly what you do not want to care about when you are trying to add a feature or serve a customer.
Having fast building blocks lets you skip all of this entirely
Fast Libraries means Simpler Code and Simpler Systems
If your building blocks are fast, often doing the dumb thing is fast enough. Rather than building a complicated hierarchical caching system for your HTML template partials, Scalatags is fast enough you can usually just re-render the whole thing every time. Rather than than setting up a multi-step code generation workflow feeding BNF grammars into lex/yacc/Bison to parse something, you can just import fastparse._ and perform define the parsing logic directly where you need to use it.
Not only does this mean less time is spent writing the code, but it has follow on effects on maintainability: simple codebases and simple systems doing simple things are easier to maintain, evolve, and extend. Every piece of complexity you did not have to add to deal with performance is complexity you would not need to maintain, debug, or onboard new colleagues onto.
Fast Libraries means Robustness
A lot of outages are fundamentally caused by performance. For example, everyone knows you’re not meant to be serving large static files from your high-QPS web and API servers. If you start serving huge binary blobs from your Python webservers, things are going to fall down hard. If you’re serving huge binary blobs from your Cask webservers, from experience things can keep chugging along remarkably well.
Having "excess" performance in reserve can easily be the difference between an outage/post-mortem, and a low-priority "fix the sub-optimal architecture" roadmap item.
Fast Libraries means Fewer Rewrites
Fast building blocks means your "prototype" codebase and your "production" codebase can be one-and-the-same.
Rather than building your language prototype in scala-parser-combinators and then re-writing it as hand-rolled recursive descent after, you can just use FastParse once and be done with it. Rather than writing a proof-of-concept in Python and rewriting it in Go/Java/Scala before release, you can build using com.lihaoyi Scala libraries and smoothly evolve that codebase from prototype to production.
Fast is easy, fast is boring. In the case of com.lihaoyi tools and libraries, being fast is not something that is done at the expense of ease of use, but is done to enhance it. The less developers have to deal with performance issues in their underlying building blocks, the more they can spend their time and energy on the actually problem that they are trying to solve.
Case Study: How Mill Makes Builds Great
For the last section of this post, we will explore the Mill build tool.
Mill is a build tool that uses these principles to make the experience of configuring your build a pleasant one. Users like complaining about build tools: about Maven, about Gradle, about SBT. But users generally have nice things to say about Mill!
Mill is so refreshing and I truly believe that the language would be much better off if newcomer's first experiences were with mill instead of sbt.
/r/kag0
I only have good things to say about mill, except maybe that I wish it had been released 10 years earlier or so :)
/r/u_tamtam
We will dive into what Mill is, how it works, and how it uses Scala as Executable Pseudocode to let you define your build in a way that is easy, boring, and fast.
Mill is probably one of the most mature alternatives to SBT today. All the projects in the com.lihaoyi ecosystem have been developed, built, and published using Mill for over half a decade. Coursier, which you all use to resolve and download third-party dependencies, is built using Mill. Scala-CLI is built using Mill. I personally haven’t touched SBT for more than 5 years now. Mill works great. People love it. Let's we’ll dive into why.
Mill as Executable Pseudocode
import mill._, scalalib._
object foo extends ScalaModule {
def scalaVersion = "2.13.8"
/** Total number of lines in modules source files */
def lineCount = T{
allSourceFiles().map(f => os.read.lines(f.path).size).sum
}
/** Generate resources using lineCount of sources */
override def resources = T{
os.write(T.dest / "line-count.txt", "" + lineCount())
super.resources() ++ Seq(PathRef(T.dest))
}
}
Mill lets you define your project’s sub-modules as objects: in this case object foo will represent the module in the foo/ folder, normally with sources in foo/src/, resources in foo/resources/ and output in out/foo/.
We're also define a new build target def lineCount, that we compute by taking all the source files and counting how many lines are within them. We then override the resources of the module to include a generated text file containing the line count, which is written to a T.dest folder which (automatically assigned as out/foo/resources).
This generated resource file can then be read at runtime, by the source code in the foo/src/ folder. e.g.
// foo/src/Foo.scala
object Foo{
def main(args: Array[String]): Unit = {
val lineCount = scala.io.Source.fromResource("line-count.txt") .mkString
println(s"Line Count: $lineCount")
}
}
You can use foo.run to run this main method, show to print out the value of any specified intermediate target, Or inspect to see the metadata information of a particular build target
$ ./mill foo.run
Line Count: 10
$ ./mill show foo.lineCount
10
$ ./mill inspect foo.lineCount
foo.lineCount(build.sc:6)
Total number of lines in modules source files
Inputs:
foo.allSourceFiles
This is a synthetic example, but it is enough to give you an idea of how Mill works. In Mill, you write more-or-less plain Scala code: you have objects that extend traits, method defs that call or override other method defs,super, and so on. That’s all Mill needs to schedule them to be built in the right order, automatically caching things, invalidating, parallelizing, and letting you inspect the build to debug it. For example, if I don’t edit any source files, my lineCount computation here will not be re-evaluated unnecessarily.
These things don’t matter so much for a toy example, but become much more important when the size and complexity of the build grows. For example, in large SBT builds it’s very common for people being puzzled why it’s slow, why certain tasks are being re-executed even when nothing material changed, or why one task causes another to be run. Mill is generally much better both at doing the "right thing" out-of-the-box, as well as providing tools to investigate these issues yourself.
Mill v.s. SBT
One thing that’s worth mentioning is how this compares to the equivalent SBT build
import sbt._, Keys._
lazy val lineCount = taskKey[Int](
"Total number of lines in modules source files"
)
lazy val foo = project.in(file(".")).settings(
name := "foo",
scalaVersion := "2.13.8",
lineCount := {
val srcFiles = (Compile / sources).value
srcFiles.map(f => IO.readLines(f).size).sum
},
Compile / resource += {
val dest = (Compile / resourceManaged).value
val count = lineCount.value
val lineCountFile = dest / "line-count.txt"
IO.write(lineCountFile, count.toString)
lineCountFile
}
)
The SBT code contains most of the same concepts: we define a lineCount task that sums up the lines from all the source files, and use that to generate some a resource file to be read at runtime. However, the same concept - e.g. defining namespaces, defining tasks, etc. - look very different in the SBT example when compared to the Mill example, and also very different from what you would expect to see in "normal" Scala code:
- Rather than
objects, we have (project in file).settingss.
- Rather than
def lineCount =, we need to do lazy val lineCount = taskKey and then lineCount := later.
- Rather than normal scaladoc comments, we need to put the lineCount documentation as a string
- Rather than
override def resources, we have Compile / resources +=
We can see from this that it’s not the conciseness or verbosity that makes or breaks executable pseudocode: the SBT example is marginally more verbose than the Mill example, but not terribly so. Rather, it is the fact that SBT code - while nominally Scala - does not look like any Scala code you would find anywhere else. You won't see code like Compile / resources += in a typical Scala application! Mill code, on the other hand, would fit right in.
As a Scala developer, you already know how objects, traits, defs, overrides, supers, and method calls work. Mill takes all that stuff you already know, and then automatically augments it with all the stuff you probably want in your build pipelines: caching, parallelism, queryability, etc. That’s why Mill code looks so familiar, especially compared to other build tools like SBT or Gradle, even for people who already know Scala or Groovy. It’s executable Scala pseudocode!
Making Mill Easy, not Simple
Many people have commented that Mill is not Simple. And it’s true: Mill aims to be Easy, not Simple. In order to give the seamless "write what you think, we’ll take care of the rest" experience shown earlier, Mill has to jump through a lot of hoops! Let’s go through some of them
Target Macros
First, T{} blocks are macros that expand into a new Target with a zipMap call, effectively turning the direct-style code into a free applicative.
- def lineCount = T{
+ def lineCount = new Target(
+ T.zipMap(Seq(allSourceFiles)) { case Seq(allSourceFiles) =>
This free applicative graph structure gives us the scheduling, parallelizability, introspectability, and other things that people want from their build tool. This is what allows e.g. using mill inspect to list out dependencies of a Target as we saw above, or mill path to find how one target depends on another:
$ ./mill path foo.run foo.lineCount
foo.lineCount
foo.resources
foo.localClasspath
foo.runClasspath
foo.run
All these are things that you cannot do with the callgraph of "normal" code. T{} is a macro. People say these macro transformations are not simple, and it’s true: they’re not. But it does make things easier.
Scaladoc Annotation Compiler Plugin
/** Total number of lines in modules source files */
+ @Scaladoc("Total number of lines in modules source files")
def lineCount = new Target(
Mill uses a compiler plugin to save the Scaladoc as an annotation, that we then fish out later using Java reflection. This is what lets us print out the Scaladoc when you mill inspect things from the command line.
Source File & Line Number Implicit Macros
allSourceFiles.map(f => os.read.lines(f.path).size).sum
},
+ line = sourcecode.Line(6),
+ fileName = sourcecode.FileName("build.sc")
)
Mill uses not just macros, not just implicits, but implicit macros from the SourceCode library to inject the line number and file name. That's why mill inspect above was able to print out (build.sc:6) as the source location at which this target was defined.
Definition Name Implicit Macros
- object foo extends ScalaModule {
+ object foo extends ScalaModule(path = outer.path / "foo") {
line = sourcecode.Line(6),
fileName = sourcecode.FileName("build.sc"),
+ path = foo.path / "lineCount"
)
Next, Mill uses the sourcecode.Enclosing implicits macros to grab the name of the objects and def. That is how Mill knows that the foo.run or foo.lineCount commands correspond to those modules and targets, and that they should read sources from the foo/src/ folder and output their caches and other metadata in the out/foo/ folder e.g. out/foo/lineCount.json
Implicit ReadWriter
line = sourcecode.Line(6),
fileName = sourcecode.FileName("build.sc"),
path = foo.path / "lineCount",
+ readWriter = upickle.default.readwriter[Int]
)
Lastly, we use implicits to resolve a upickle.default.ReadWriter, that is used to cache things on disk. This means even if we don’t keep a persistent Mill process open, after Mill shuts down a future Mill process is still able to pick things up from the cache where it left off.
Mill Fully Expanded
The expanded object foo and def lineCount ends up looking something like this:
import mill._, scalalib._
object foo extends ScalaModule(path = outer.path / "foo") {
def scalaVersion = "2.13.8"
/** Total number of lines in modules source files */
@Scaladoc("Total number of lines in modules source files")
def lineCount = new Target(
T.zipMap(Seq(allSourceFiles)) { case Seq(allSourceFiles) =>
allSourceFiles.map(f => os.read.lines(f.path).size).sum
},
line = sourcecode.Line(6),
fileName = sourcecode.FileName("build.sc"),
path = foo.path / "lineCount",
readWriter = upickle.default.readwriter[Int]
)
/** Generate resources using lineCount of sources */
override def resources = T{
os.write(T.dest / "line-count.txt", "" + lineCount())
super.resources() ++ Seq(PathRef(T.dest))
}
}
This expanded code is not Simple: there's a lot of stuff here, from Free Applicatives to Typeclass JSON serializers to Java annotations. Neither are the transformations that brought us here: Java Reflection, Compiler Plugins, Implicits, Macros, Implicit Macros.
However, all this complexity is towards one purpose: to make life Easy for the person configuring the build! To them, they just need to write their Scala code as it were pseudocode from an intro-to-Scala class - with objects, traits, and defs. Methods that call other methods. override and super. All the other "stuff" around build tooling is done for them, rather than by them: incremental computation, caching, parallelism, introspectability, and so on. Mill uses its complexity budget to ensure there’s fewer things that a user would need to care about, rather than more. That's how Mill aims to be Easy, not Simple.
Mill is Fast
Lastly, Mill tries to help make your builds fast.
As a start, Mill allows parallelism: you can pass in how many parallel jobs you want, e.g. -j 6 gives you 6 parallel jobs
$ ./mill -j 6 __.compile
Mill will then run everything using 6 threads, scheduling things appropriately in dependency order. Note that our Mill example earlier had no parallelism-related code in it at all! Just by defining an (almost) normal object with (almost) normal defs, Mill is able to generate a dependency-graph between the various definitions and automatically parallelize the parts that do not depend on each other.
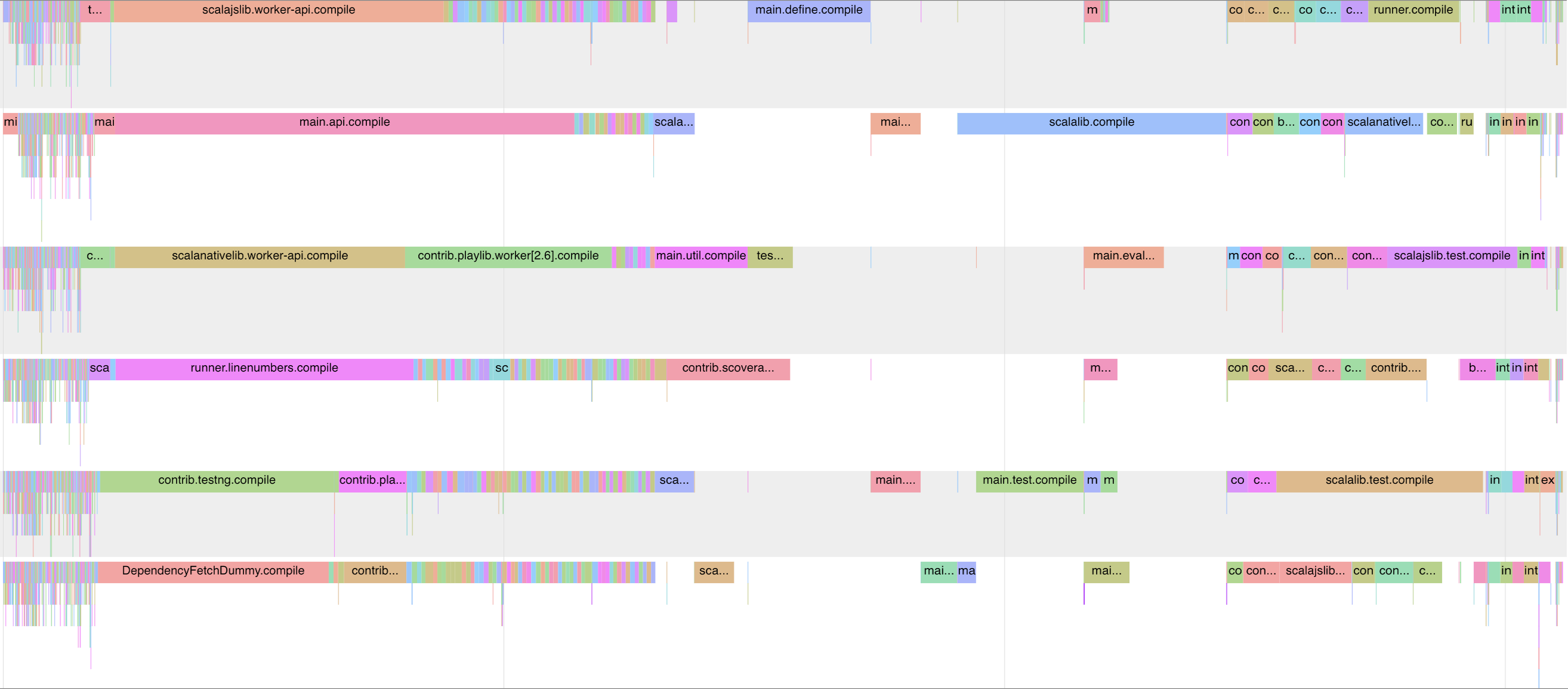
Mill also generates a nice profile you can load into chrome to see where your time is being spent. This example below is from running ./mill -j 6 __.compile on the https://github.com/com-lihaoyi/mill repo, to give a slightly more meaty project than the trivial Mill example snippet we've discussed so far:
This makes it easy to see where the slowness are, e.g.
-
The blue main.define.compile segment in the top-middle which is running alone after all the segments on the left run in parallel, and needs to complete before all the segments on the right run in parallel.
-
The blue scalalib.compile to the bottom-right of it also seems to be a bottleneck before a lot of downstream tasks can begin. Apart from the bottlenecks.
-
Some tasks are just slow: scalajslib.worker.api.compile, main.api.compile, scalanativelib.worker.api.compile on the left are all taking considerable amounts of time to run, even if they're running in parallel with other tasks.
This is valuable information to someone trying to figure out why their build is slow, and how they can make it faster!
While Mill goes to great efforts to make its own internal implementation reasonably fast, in any build tool the bottleneck often is the user-defined build steps or build actions. Mill makes it easy to triage the performance of your build, so you can figure out what parts of your own Mill build are slow, and do something about it.
Conclusion
Scala, despite being a language as concise as Python, has never taken off as an "Executable Pseudocode". This blog examined how existing Scala libraries are sufficiently clunky that they make using "Scala as Pseudocode" impossible, and how the com.lihaoyi libraries work to resolve that problem. We also examined three other principles of the com.lihaoyi libraries: aiming for Easy, Boring, and Fast, resulting in a developer experience that is very different from that of traditional Scala frameworks.
Lastly, we did a deep dive into the Mill build tool, examining both how it presents a concise, familiar and intuitive API to users - "Executable Pseudocode". We discussed how it sacrifices simplicity, using a veritable zoo of complicated techniques to make life as easy as possible for the user. We touched on performance, how Mill supports parallelism and generates profiles for you to easily understand and improve the performance of your project build setup. All that is how Mill has become a build tool its users love, rather than hate.
For further reading, check out the links below:
All the libraries in the com.lihaoyi ecosystem are listed and maintained there. These are open source projects, and we always need more people of all stripes helping to use, maintain, and improve these libraries.
-
If you are an existing Scala developer already using Cats or Akka or ZIO or something else, these small libraries can fit right in.
-
If you are new to Scala, com.lihaoyi is a great foundation on which to learn the language.
-
If you had already tried Scala in the past and been put off by its Strangeness, the com.lihaoyi tools and libraries might be able to change your mind by showing how Scala can be easy and intuitive.
Hand-on Scala Programming Book
This book is a systematic tour of how to use the Scala - supported by the com.lihaoyi ecosystem - to build a lot of projects with real-world applicability. While other Scala books might have you re-implementing linked lists and fibonacci functions, Hands-on Scala has you implementing parallel web-crawlers, realtime web-sites, networked Scala applications, programming language interpreters, and many other things that your employer may pay real money for you to do. The first 5 chapters are free on the book's website.
The book’s example projects are also available for free online. Even without the book, this is a great resource for the question of "how do I do X" using the com.lihaoyi libraries. All 143 examples are free online, complete with test suites
Lastly, if anyone reading this is a Scala developer who does not like SBT, you should take some time to try out the Mill build tool. We just released version 0.11.0, with a ton of improvements by both myself and other contributors.
People like saying that SBT is a problem, confusing newbies and veterans alike, and holding Scala back from widespread adoption. But there is an alternative to SBT - It’s Mill - and many of us have been using Scala without SBT for years now. You definitely should try it out and see how great the post-SBT world is!
About the Author: Haoyi is a software engineer, and the author of many open-source Scala tools such as the Ammonite REPL and the Mill Build Tool. If you enjoyed the contents on this blog, you may also enjoy Haoyi's book Hands-on Scala Programming